Einführung in das Forschungsdatenmanagement
Dieser Text ist eine an die Fachdisziplin angepasste Fassung des Textes „Einführung in das Forschungsdatenmanagement“ aus Data Affairs von Camilla Heldt und Birgitt Röttger-Rössler, lizenziert unter CC BY-SA 4.0.
Einführung
Mit dem Aufkommen der globalen Open-Science(OS)-Bewegung'Die Open-Science-Bewegung plädiert seit den frühen 2000er Jahren für eine offene und transparente Wissenschaft, in der alle Schritte des wissenschaftlichen Erkenntnisprozesses offen online zugänglich gemacht werden. So sollen nicht nur Endergebnisse von Forschungen wie Monographien oder Artikel öffentlich geteilt werden, sondern auch verwendete Materialien, die den Entstehungsprozess begleiteten wie: Labortagebücher, Forschungsdaten, verwendete Software, Forschungsberichte usw. Dadurch soll eine Partizipation an Wissenschaft und Erkenntnissen gefördert und interessierte Öffentlichkeiten angesprochen werden. Kreativität, Innovation und neue Kollaborationen sollen gefördert, Erkenntnisse auf ihre Qualität, Richtigkeit und Authentizität hin überprüft werden, was eine Demokratisierung von Forschung bezwecken soll. Zur Open Science zählen u. a. Open Access und Open Data, die Infrastrukturen des Teilens von Zwischenergebnissen von Forschungen bilden.' (Data Affairs, Glossar) Weiterlesen in den frühen 2000er Jahren hat sich der Anspruch an eine verantwortungsvolle Forschung und eine gute wissenschaftliche Praxis'Die gute wissenschaftliche Praxis (GWP) bildet einen standardisierten Kodex, der als Regelwerk in den Leitlinien der Deutschen Forschungsgemeinschaft (DFG) verankert ist. Die Leitlinien verweisen auf die ethische Verpflichtung jedes/jeder Forschenden, verantwortungsvoll, ehrlich und respektvoll vorzugehen, auch um das allgemeine Vertrauen in Forschung und Wissenschaft zu stärken. Sie können als Orientierung im Rahmen wissenschaftlicher Arbeitsprozesse geltend gemacht werden.' (Data Affairs, Glossar) Weiterlesen (GWP) weiterentwickelt. GWP bildet einen standardisierten Kodex, der in den Leitlinien der Deutschen Forschungsgemeinschaft (DFG) verankert ist und zu einem ehrlichen und verantwortungsvollen, sowie ethisch und rechtlich einwandfreien wissenschaftlichen Arbeiten verpflichtet (DFG, 2022). Immer stärker rücken Forderungen nach Open Access'Open Access bezeichnet den freien, kostenlosen, ungehinderten und barrierefreien Zugang zu wissenschaftlichen Erkenntnissen und Materialien. Für eine weitere rechtssichere Nachnutzung der Materialien durch Dritte müssen die Urhebenden mittels Lizenzvertrages die Nutzungsrechte an ihren Werken einräumen. Die freien CC-Lizenzen spezifizieren bspw. genau, wie Daten und Materialien weitergenutzt werden dürfen. Weiterlesen – einem offenen und kostenlosen Zugang zu wissenschaftlicher Literatur – und damit nach Open Data'Open Data (offene Daten) sind Daten, die offen und frei online zugänglich sind sowie uneingeschränkt von Dritten weiterverwendet werden dürfen. Dies setzt voraus, dass sie mit einer offenen Lizenz versehen sind (Opendefinition 2023).' (Data Affairs, Glossar) Weiterlesen – der Möglichkeit des offenen Zugangs zu und der Nachnutzung von Forschungsdaten durch Dritte – in den Vordergrund. Die Forderungen nach Open Science sind in den Richtlinien und Empfehlungen der DFG verankert und haben zum Ziel, die akademische Forschung für unterschiedliche Öffentlichkeiten zugänglich zu gestalten. Damit soll das allgemeine Vertrauen in die Wissenschaft gestärkt und Kreativität, Innovationen und Kollaborationen gefördert werden.
Im Sinne der FAIR-Prinzipien'Die FAIR-Prinzipien wurden 2016 erstmals von der FORCE 11-Community (The Future of Research Communication and e-Scholarship) entwickelt. FORCE11 ist eine Gemeinschaft von Wissenschaftlern, Bibliothekaren, Archivaren, Verlegern und Forschungsförderern, die durch den effektiven Einsatz von Informationstechnologie einen Wandel in der modernen wissenschaftlichen Kommunikation herbeiführen und so eine verbesserte Wissenserstellung und -weitergabe unterstützen will. Das primäre Ziel liegt in der transparenten und offenen Darlegung wissenschaftlicher Erkenntnisprozesse. Demnach sollten Daten online findable (auffindbar), accessible (zugänglich), interoperable (kompatibel) und reusable (wiederverwendbar) abgelegt und strukturiert sein. Ziel ist es, Daten langfristig aufzubewahren und im Sinne der Open Science und des Data Sharing für eine Nachnutzung durch Dritte bereitzustellen. Genaue Definitionen der FORCE11 selbst können auf der Website nachgelesen werden siehe: https://force11.org/info/the-fair-data-principles/. Die FAIR-Prinzipien berücksichtigen ethische Aspekte der Weitergabe von Daten in sozialwissenschaftlichen Kontexten nicht hinreichend, weshalb sie um die CARE-Prinzipien ergänzt wurden.' (Data Affairs, Glossar) Weiterlesen, die 2016 erstmals von der FORCE11-Community (The Future of Research Communication and e-Scholarship) veröffentlicht wurden, sollen wissenschaftliche Erkenntnisse auch in ihrem Entstehungsprozess transparent und offen zirkulieren (Force, 2021). Daten sollen auffindbar (findable), zugänglich (accessible), interoperabel'Unter Interoperabilität bezeichnet man die Fähigkeit eines Systems mit anderen Systemen nahtlos zusammenzuarbeiten. Innerhalb interoperabler Systeme können Daten automatisiert mit anderen Datensätzen kombiniert und ausgetauscht werden. Somit werden Daten auf vereinfachte und beschleunigte Weise maschinell lesbar, interpretierbar und vergleichbar. Interoperabilität stellt eines der Hauptkriterien der FAIR-Prinzipien dar (Forschungsdaten.info 2026).' (Data Affairs, Glossar) Weiterlesen bzw. kompatibel (interoperable) und wiederverwendbar (reusable) strukturiert, dokumentiert und abgelegt werden. Durch einen uneingeschränkten Zugang zu Wissen soll die Partizipation an akademischen Diskursen für breite Öffentlichkeiten ermöglicht und eine Demokratisierung von Forschung angestrebt.

Grafik: FAIR-Prinzipien (nach Paulina Halina Sieminska), Anne Voigt mit CoCoMaterial, 2025, lizenziert unter CC BY-SA 4.0
Dabei steht insbesondere das Forschungsdatenmanagement (FDM) im Fokus: FDM bildet das Schlüsselkonzept verantwortungsvoller, guter wissenschaftlicher Praxis und beinhaltet den Umgang mit Forschungsdaten in Bezug auf ihre Organisation, Pflege und Aufarbeitung anhand spezifischer Maßnahmen und Strategien. Ziel ist es, Daten im Sinne der FAIR-Prinzipien langfristig aufzubewahren und für Dritte zugänglich zu machen, sodass wissenschaftliche Aussagen überprüft, Nachweise gesichert und weitere Auswertungen oder Analysen vollzogen werden können. Hier greift der Imperativ des Data Sharing'Data Sharing meint das Teilen bzw. Weitergeben von Daten. Dabei gilt es gemäß den entsprechenden Anforderungen der Forschung, die Daten so offen wie möglich und so geschlossen wie nötig (Europäische Kommission 2021) darzulegen und zur Verfügung zu stellen. Insbesondere im Hinblick auf die Nachnutzung und den Umgang mit sensiblen, personenbezogenen Daten muss gründlich überprüft werden, ob und in welcher Form das Archivieren und Teilen von Daten mit anderen Wissenschaftler*innen und der Öffentlichkeit möglich und sinnvoll ist. Der Imperativ des Data Sharing bildet im Rahmen der Open-Science-Bewegung einen breiten Konsens in der Wissenschaft, ist aber aus sozial- und kulturanthropologischer Sichtweise kritisch zu betrachten und abzuwägen.' (Data Affairs, Glossar) Weiterlesen, also des Teilens bzw. der Weitergabe von Daten: Gemäß den Anforderungen von Open Science'Der Begriff Open Science bündelt … Strategien und Verfahren, die allesamt darauf abzielen, ... alle Bestandteile des wissenschaftlichen Prozesses über das Internet offen zugänglich und nachnutzbar zu machen. Damit sollen Wissenschaft, Gesellschaft und Wirtschaft neue Möglichkeiten im Umgang mit wissenschaftlichen Erkenntnissen eröffnet werden' (Open Science AG 2014). Weiterlesen gilt es, erhobene Daten „as open as possible and as closed as necessary“ (Europäische Kommission, 2021) zur Verfügung zu stellen.
Aspekte des Forschungsdatenmanagements gewinnen in den letzten Jahren zunehmend an Bedeutung, sodass immer mehr Universitäten, Forschungs- und Förderinstitutionen eigene Forschungsdatenpolicies formulieren. Diese Leitlinien und Regelwerke bieten Orientierung bei Fragen bezüglich des FDM und sollten in der Umsetzung beachtet werden. Es gibt in Deutschland zwar noch keine allgemeingültigen Vorgaben zum Umgang mit Forschungsdaten, dennoch fordern zunehmend Forschungsförderer wie die DFG, das BMBF oder der EU entsprechende Nachweise oder Pläne (wie z. B. einen Datenmanagementplan'Ein Datenmanagementplan (DMP) beschreibt und dokumentiert den Umgang mit den Forschungsdaten und Forschungsmaterialien einer Forschung während und nach der Projektlaufzeit. Im DMP wird festgehalten, wie die Daten und Materialien entstehen, aufbereitet, gespeichert, organisiert, veröffentlicht, archiviert und ggf. geteilt werden. Zudem werden im DMP Verantwortlichkeiten und Rechte geregelt. Als 'living document' (also ein dynamisches Dokument, das sich fortlaufend in Bearbeitung und Veränderung befindet) wird der DMP im Laufe des Projektes regelmäßig geprüft und bei Bedarf angepasst.' (Data Affairs, Glossar) Weiterlesen) verpflichtend ein.
Hinsichtlich eines empfohlenen, sorgfältigen Forschungsdatenmanagements kann ferner das Modell des Forschungsdatenlebenszyklus'Das Modell des Forschungsdatenlebenszyklus stellt sämtliche Phasen dar, die Forschungsdaten vom Zeitpunkt der Erhebung bis zu ihrer Nachnutzung durchlaufen können. Die Phasen sind an bestimmte Aufgaben gekoppelt und können variieren (Forschungsdaten.info 2026). Allgemein umfasst der Forschungsdatenlebenszyklus folgende Teilbereiche: Weiterlesen als unterstützendes Hilfsmittel herangezogen werden: Innerhalb dieses Konzeptes werden einzelne „Lebensstadien“ von Daten unterschieden und mit bestimmten Aufgaben verbunden, die vor, während und nach der Datenerhebung anfallen. Diese beinhalten die Planung des Forschungsvorhabens, die Datenerhebung als solche, die Aufarbeitung und Analyse von Daten, die Datenpublikation sowie die Archivierung und Nachnutzung. Mit der Metapher des Lebenszyklus werden Daten als „lebendige“ Entitäten betrachtet, die auch über das einzelne Forschungsprojekt hinaus (z. B. durch eine Nachnutzung'Eine Nachnutzung, oftmals auch Sekundärnutzung genannt, befragt bereits erhobene und veröffentlichte Forschungsdatensätze erneut mit dem Ziel, andere Erkenntnisse, möglicherweise aus einer neuen oder unterschiedlichen Perspektive, zu erhalten. Die Aufbereitung von Forschungsdaten für eine Nachnutzung erfordert einen erheblich höheren Anonymisierungs-, Aufbereitungs- und Dokumentationsaufwand als die bloße Archivierung im Sinne von Datenspeicherung.' (Data Affairs, Glossar) Weiterlesen) ein „eigenes Leben“ führen.
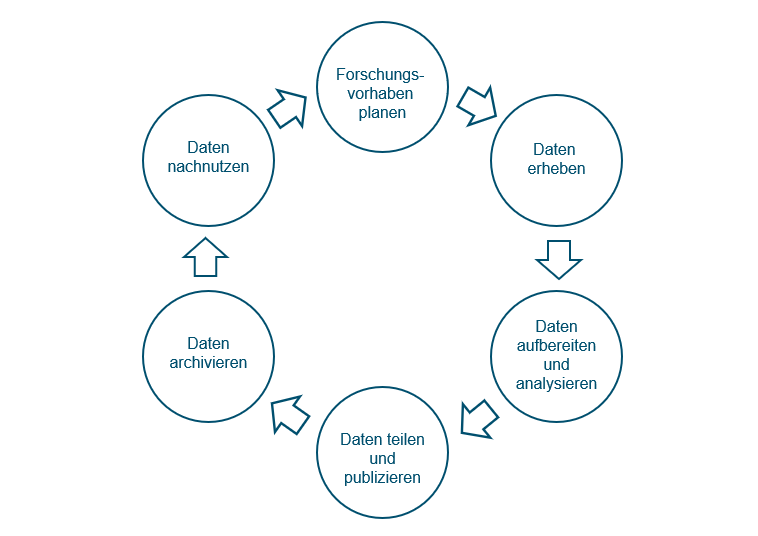
Grafik: Forschungsdatenlebenszyklus, Anne Voigt nach forschungsdaten.info, 2025, lizenziert unter CC BY-SA 4.0
Die oben beschriebenen FAIR-Prinzipien, die Leitlinien der Forschungseinrichtungen und Drittmittelgeber sowie der Forschungsdatenlebenszyklus stellen Empfehlungen für ein erfolgreiches Forschungsdatenmanagement dar, berücksichtigen allerdings forschungsethische Aspekte und Problematiken nur am Rande. Daher wurden 2019 von der Research Data Alliance, die einen technischen und sozialen infrastrukturellen Ausbau von Data Sharing anstrebt, die CARE-Prinzipien'Die CARE-Prinzipien wurden 2019 von der Global Indigenous Data Alliance (GIDA) etabliert. Sie fungieren als Komplement zu den FAIR-Prinzipien und gelten als Hilfswerkzeug, um Forschungskontexte und ihre historische Einbettung sowie Machtasymmetrien im Feld stärker zu fokussieren. Das Akronym steht für Collective Benefit (Gemeinwohl), Authority to Control (Kontrolle der Forschungsteilnehmenden über die eigene Repräsentation), Responsibility (Verantwortung seitens Forschender) und Ethics (Berücksichtigung ethischer Aspekte). Durch die CARE-Prinzipien soll der gerechte, respektvolle und ethische Umgang mit Forschungsteilnehmenden und den aus der Forschung generierten Daten hinsichtlich des Data Sharing betont und berücksichtigt werden. Die CARE-Prinzipien sind somit in allen Phasen des Forschungsdatenlebenzyklus und des Forschungsdatenmanagements relevant.' (Data Affairs, Glossar) Weiterlesen formuliert. Sie sollen als Ergänzung der FAIR-Prinzipien fungieren und sind besonders für die historische Forschung im Bereich der Area Studies, der Kolonialgeschichte und indigener Gemeinschaften bedeutend.
Motivation
Es gelten folgende Faktoren als motivierend in Bezug auf das Forschungsdatenmanagement:
- Bestimmte Förderinstitutionen fordern Strategien des FDM (wie z. B. einen Datenmanagementplan) als Voraussetzung für die Förderung (vgl. Artikel zum Datenmanagementplan).
- Durch die Einhaltung von FDM-Prozessen „von Anfang an“ erleichtern sich Forschende nicht nur die eigene spätere Re-Interpretation ihrer Daten, sondern verringern auch den Aufwand für die Bereitstellung ihrer Daten zur Nachnutzung durch Dritte.
- Für die Reproduzier- bzw. Nachvollziehbarkeit von Forschungsergebnissen ist ein gut dokumentiertes FDM Voraussetzung (RatSWD, 2023, p. 8).
- Das Risiko eines Datenverlusts wird durch FDM-Maßnahmen wie zur Datensicherheit'Unter Datensicherheit werden alle präventiven Maßnahmen physischer und technischer Art verstanden, die dem Schutz digitaler und auch analoger Daten dienen. Datensicherheit soll für deren Verfügbarkeit bürgen, sowie die Vertraulichkeit und Integrität der Daten gewährleisten. Beispiele für Maßnahmen sind: Passwortschutz für Geräte und Online-Plattformen, Verschlüsselungen für Software z. B. E-Mails und auch Hardware, Firewalls, regelmäßige Softwareupdates sowie sicheres Löschen von Dateien.' (Data Affairs, Glossar) Weiterlesen sowie -speicherung'Datenspeicherung bezeichnet allgemein den Vorgang des Speicherns von Daten auf einem Trägermaterial oder Datenträger (digitalisierte Daten). Forschungsdaten sind einzigartige, wertvolle Daten, die sicher aufbewahrt werden sollten, um sie vor Verlust und fremden Zugriff zu schützen. Mit verschiedenen Maßnahmen wie z. B. regelmäßigen Backup-Routinen (Sicherheitskopien) kann ein möglicher Datenverlust minimiert werden.' (Data Affairs, Glossar) Weiterlesen, eine systematische Datendokumentation'Forschungsdaten bilden nicht nur die Basis wissenschaftlicher Veröffentlichungen der jeweiligen Forscher*innen, sondern werden in vielen Fällen anderen zugänglich gemacht. Dies setzt voraus, dass Forschungsdaten verständlich dokumentiert sind. Unverzichtbar wird dies, wenn eine Datenpublikation beabsichtigt ist. Eine zentrale Rolle für das Finden, Durchsuchen und Nutzen von Forschungsdaten spielen Metadaten, also Daten, die strukturierte Informationen über andere Daten enthalten. In verschiedenen Wissenschaftskreisen haben sich für die Dokumentation in Form von Metadaten sogenannte Metadatenstandards etabliert, die Konventionen für die Beschreibung und Dokumentation von Forschungsdaten über Metadaten festlegen. Weiterlesen und eine geeignete Langzeitarchivierung (LZA) minimiert.
- Ein gutes FDM unterstützt die Umsetzung der FAIR-Prinzipien.
Dennoch bedeutet Forschungsdatenmanagement nicht unbedingt, dass Daten offen zugänglich sein müssen. Es können rechtliche (z. B. Urheber- und Nutzungsrechte) oder ethische Gründe dem Open-Science-Gedanken entgegenstehen. Hier müssen die Interessen der verschiedenen Parteien abgewogen und die Implikationen auf die Durchführbarkeit des Forschungsprojektes berücksichtigt werden.
Vorgehen
Die Maßnahmen und Strategien des FDMs umfassen folgende Bereiche, auf die in den weiteren Artikeln vertiefend eingegangen wird:
- Planung des Forschungsvorhabens: Entwicklung des Arbeitsprogramms anhand der Ziele und Methoden unter Berücksichtigung des Datenmanagements und dessen Dokumentation in einem Datenmanagementplans (DMP)'Ein Datenmanagementplan (DMP) beschreibt und dokumentiert den Umgang mit den Forschungsdaten und Forschungsmaterialien einer Forschung während und nach der Projektlaufzeit. Im DMP wird festgehalten, wie die Daten und Materialien entstehen, aufbereitet, gespeichert, organisiert, veröffentlicht, archiviert und ggf. geteilt werden. Zudem werden im DMP Verantwortlichkeiten und Rechte geregelt. Als 'living document' (also ein dynamisches Dokument, das sich fortlaufend in Bearbeitung und Veränderung befindet) wird der DMP im Laufe des Projektes regelmäßig geprüft und bei Bedarf angepasst.' (Data Affairs, Glossar) Weiterlesen
- Datenorganisation (z. B. Speichersysteme, Ablageordnung, Kollaboration, Zugriffssteuerung, Data Policy)
- Quellensammlungsstrategien (z. B. Recherche, Repositorien'Ein Repositorium bildet einen Ort der Aufbewahrung wissenschaftlicher Dokumente. In Online-Repositorien werden Publikationen digital gespeichert, verwaltet und mit persistenten Identifikatoren versehen. Die Katalogisierung vereinfacht die Suche und Nutzung von Publikationen und Autor*innen. In den meisten Fällen sind Dokumente in Online-Repositorien uneingeschränkt und offen zugänglich (Open Access).' (Data Affairs, Glossar) Weiterlesen, DigitalisierungBei der Digitalisierung werden analoge Materialien in digitale Formate, sog. Digitalisate, überführt. Diese Formate können weitergegeben, gespeichert, archiviert und maschinell verarbeitet werden. Weiterlesen, Aufzeichnung von Oral History Interviews)
- Datenerhebung und -erschließung (z. B. Datenmodellierung, automatisierte Erschließungsverfahren, Metadatenstandards, digitale Quellenkritik, Korpusbildung)
- Aufbereitung, Analyse, Auswertung, Visualisierung und Interpretation von Daten durch (digitale) Methoden und mit Hilfe von Softwaretools
- DatenqualitätDatenqualität (in historisch arbeitenden Fächern) ist ein Maß für den Zustand von Daten hinsichtlich quantitativer Merkmale wie Genauigkeit und Vollständigkeit sowie qualitativer Aspekte wie Relevanz und Nachvollziehbarkeit. Dabei gibt es keinen absoluten Qualitätsmaßstab: Was als qualitativ hochwertig gilt, hängt stets vom konkreten Forschungsvorhaben, der zugrundeliegenden Fragestellung und der angewandten Methode ab.In historisch arbeitenden Fächern treten zwei spezifische Herausforderungen hinzu. Erstens sind historische Forschungsdaten in außerordentlicher inhaltlicher Vielfalt und struktureller Heterogenität überliefert – von Handschriften und Drucken über Fotografien und Tonaufnahmen bis hin zu nativ digitalen Datensätzen. Welche Kontextinformationen zu einer Quelle erfasst werden müssen, ist dabei nicht absolut bestimmbar, sondern ergibt sich neben der Quellentypspezifik aus der jeweiligen Fragestellung: Denn die Kontextualisierung einer Quelle könnte theoretisch unbegrenzt fortgesetzt werden, ist in der Praxis aber auf das für den Forschungszweck Notwendige beschränkt. Zweitens sind historische Daten grundsätzlich durch Überlieferungslücken und Unschärfen geprägt: Bestimmte Informationen sind schlicht nicht mehr rekonstruierbar, was Vollständigkeit als Qualitätskriterium im historischen Kontext nur bedingt anwendbar macht. Datenqualität bedeutet hier daher weniger das Erreichen eines absoluten Vollständigkeitsideals als vielmehr die transparente Dokumentation dessen, was vorhanden ist, was fehlt und warum (vgl. Körfer 2026). Weiterlesen durch Daten- und Prozessdokumentation und Verwendung von (Meta)Datenstandards (z. B. TEITEI (Text Encoding Initiative) bezeichnet sowohl eine Organisationsiehe unter: https://tei-c.org/ als auch ein gleichnamiges Dateiformat. Letzteres basiert auf XML (Extensible Markup Language), einer weit verbreiteten Auszeichnungssprache, und hat sich in den Geisteswissenschaften als Standard zur Kodierung und Auszeichnung von Texten durchgesetzt. Mit Hilfe von TEI ist es möglich, maschinenlesbar Elemente eines Textes auszuzeichnen, wie beispielsweise Absätze oder Überschriften.Die Spezifikation von TEI - auch Guidelines genannt - kann unter https://tei-c.org/release/doc/tei-p5-doc/en/html/index.html eingesehen werden. Zudem können Inhalte wie Personen- oder Ortsnamen als solche markiert und Anmerkungen eines kritischen Apparates eingefügt werden. Im Hinblick auf das Forschungsdatenmanagement ist es vorteilhaft, dass es sich bei TEI um ein Nur-Text-Format handelt, es also auch ohne spezielle Programme von Menschen interpretiert werden kann. Weiterlesen, EAD, CEI, DDI)
- Recht (Urheberrecht'Das Urheberrecht (UrhG) schützt bestimmte geistige Schöpfungen (Werke) und Leistungen. Unter Werke fallen Sprachwerke, Lichtbild-, Film- und Musikwerke sowie Darstellungen wissenschaftlicher oder technischer Art, wie Zeichnungen, Pläne, Karten, Skizzen, Tabellen und plastische Darstellungen (Gesetz über Urheberrecht und verwandte Schutzrechte 2021, §2). Die künstlerischen, wissenschaftlichen Leistungen von Personen oder die getätigte Investition gelten dagegen als schützenswerte Leistungen (Leistungsschutzrecht). Der*die Urheber*in ist berechtigt, das Werk zu veröffentlichen und zu verwerten.' (Data Affairs, Glossar) Weiterlesen, Nutzungs- und Archivrecht, Datenschutz, Lizenzen)
- Datenpublikation (z. B. Rechte, Lizenzen, Repositorienauswahl, PID'Ein Persistent Identifier (PID) (auf Deutsch: dauerhafter Identifikator) ist ein dauerhafter, digitaler Code, der einer digitalen Ressource wie z. B. einem Datensatz, einem wissenschaftlichen Artikel oder einer anderen Veröffentlichung direkt zugeordnet ist und diese damit permanent identifizier- und auffindbar macht. Im Gegensatz zu anderen seriellen Identifikatoren (beispielsweise URL-Adressen) verweist ein Persistent Identifier auf das Objekt selbst und nicht auf seinen Standort im Internet. Ändert sich der Standort eines mit einem Persistent Identifier assoziierten digitalen Objekts, so bleibt der Identifikator derselbe. Es muss lediglich in der Identifikator-Datenbank der URL-Standort geändert oder ergänzt werden. So wird sichergestellt, dass ein Datensatz dauerhaft auffindbar, abrufbar und zitierbar bleibt (Forschungdaten.info 2023). Weiterlesen)
- Langzeitarchivierung und Nachnutzungsszenarien (Repositorienauswahl)
Bei besonderen Forschungsvorhaben wie Oral History Interviews auch:
- Maßnahmen zum Schutz von personenbezogenen oder sensiblen Daten (z. B. Anonymisierung, informierte Einwilligung, Datenverschlüsselung)
- Umsetzung ethischer Vorgaben
Anwendungsbeispiele
Beispiel 1: Zusammenspiel von Forschungsprozess und Datenmanagement am Beispiel der Entstehungsgeschichte der Regesta Imperii
Forschungsdatenmanagement ist nicht losgelöst vom Forschungsprozess, sondern eng mit ihm sowie dem gesamten Projektmanagement verbunden, wie anhand des Beispiels der Regesta Imperii sichtbar wird.
Die Regesta Imperii ist ein Beispiel für eine digitale Edition, die ein traditionsreiches und prägendes Projekt für die Mittelalterforschung aus dem Gedruckten in die digitale Welt schrittweise überführt und zusätzlich mit genuin digitalen Methoden anreichert1Siehe unter: https://dhmuseum.uni-trier.de/node/463.
Sie steht seit den 1990er Jahren für die digitale Bereitstellung von Forschungsdaten. Bereits 1998 wurde die erste CD-Ausgabe zu Friedrich III veröffentlicht, ab 2001 wurden im Rahmen eines DFG-Projekts alle Regesten digitalisiert und zur Verfügung gestellt, erst einmal ohne Tiefenerschließung. Durch das RI-Lab, welches 2023/2024 veröffentlicht wurde, werden die Regesten und zusätzliche Projektdaten über eine GitLab-InstanzModerne Softwareentwicklung findet in aller Regel über speziell dafür entwickelte Plattformen statt, die Methoden zum Projektmanagement und der Verwaltung des Quellcodes bieten. Für Letzteres hat sich das Tool git als De-Facto-Standard etabliert. Softwareentwicklungsplattformen bieten die Möglichkeit, die Entwicklung projektzentriert durchzuführen und neben dem Quellcode beispielsweise ein Wiki zu pflegen und Fehler mittels eines Issue-Trackers nachzuverfolgen. Über diesen können auch Nutzer*innen von Software Fehler melden. Diese Plattformen bieten auch weitere Mechanismen zur Automatisierung, z. B. das automatische Erstellen von lauffähigen Programmen aus dem Quellcode, die dann zum Herunterladen angeboten werden können. Weiterlesen mit dem expliziten Ziel der Nachnutzung unter einer CC-Lizenz'Creative-Commons-Lizenzen sind von der Non-Profit-Organisation Creative Commons vorgefertigte Lizenzverträge, mit denen die Urheberrechtsinhabenden der Öffentlichkeit die Nutzungsrechte am eigenen kreativen Werk einräumen können. Sobald ein unter CC-Lizenz stehendes Werk im Sinne des Lizenzvertrages von Dritten genutzt wird, kommt der Vertrag zustande (TUM 2023, 5). Weiterlesen zur Verfügung gestellt2Siehe unter: https://adwmainz.pages.gitlab.rlp.net/regesta-imperii/lab/ri-lab/. Das Register wird fortlaufend gepflegt, die Daten weiter erschlossen und mit Meta- und Normdaten ausgezeichnet sowie mit einer Literaturdatenbank referenziert3Siehe unter: http://www.regesta-imperii.de/unternehmen/ri-online.html.
Die Regesten sind durch die Erschließung facettiert durchsuchbar und stehen für verschiedene Forschungsprojekte zur Nachnutzung zur Verfügung. Die folgende Grafik veranschaulicht, wie eng der Forschungsdatenlebenszyklus und damit das Forschungsdatenmanagement insgesamt mit dem Forschungsprozess im Fall der Regesta Imperii verbunden sind.
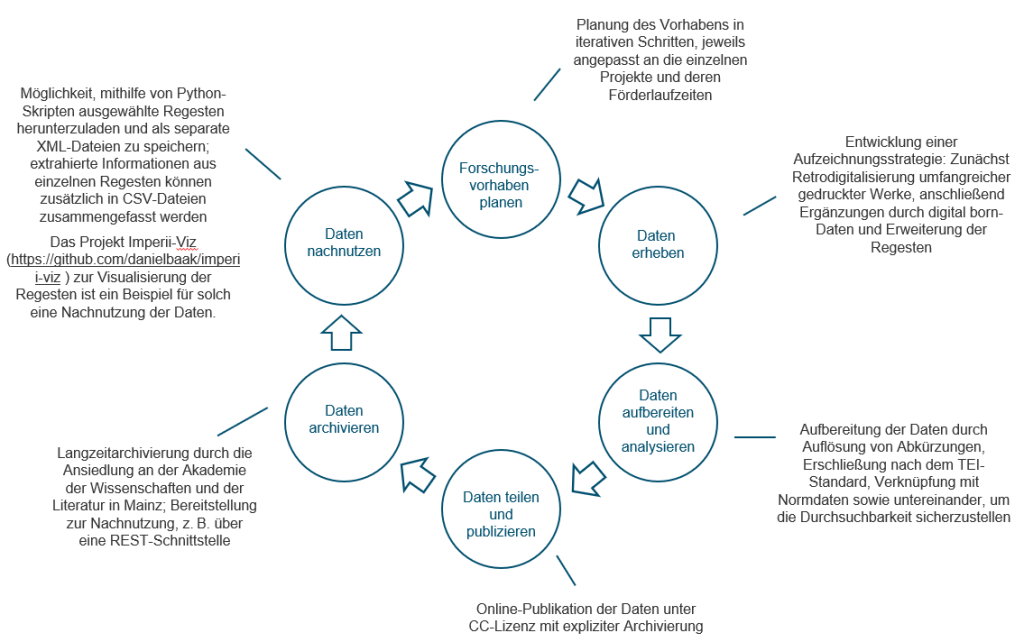
Grafik: Zusammenspiel von Forschungsprozess und Datenmanagement am Beispiel der Regesta Imperi, Laura Döring und Anne Voigt, 2025, lizenziert unter CC BY-SA 4.0
Beispiel 2: Gentz digital als Beispiel für eine Plattform zur Recherche in digital verfügbaren Forschungsdaten
Friedrich Gentz (1764 - 1832) war ein Publizist und Politiker in den auf die französische Revolution folgenden Umbruchsjahren. In seinen staatspolitischen Schriften wandelte er sich von einem Befürworter der Revolution zu einem entschiedenen Gegner der Volkssouveränität. Er war ein enger Mitarbeiter Metternichs und hatte als solcher auch Einfluss auf den Wiener Kongress (vgl. Rumpel 1964). Als Publizist und Berater pflegte Gentz ein entsprechend großes Netzwerk an Kontakten, mit denen er sich brieflich austauschte. Die Sammlung Gentz digital hat es sich zur Aufgabe gesetzt, diese Briefe zu erschließen und, versehen mit Metadaten, in Form von Transkripten und Bilddigitalisaten digital zur Verfügung zu stellen.
Wie bei vielen umfangreichen Forschungsprojekten hat auch Gentz digital eine entsprechend lange Vorgeschichte und Laufzeit, die zu einer stückweisen Entstehung des aktuellen Ergebnisses aus entsprechenden Vorgängervorhaben geführt haben. Die dadurch bedingten Medien- und Technologiewechsel, die Veränderungen in der Bereitstellung sowie unterschiedliche Projekt- und Mitarbeiterkonstellationen veranschaulichen die Notwendigkeit eines gewissenhaften FDM. Dies begann im vorliegenden Beispiel bereits bei der Sammlung Herterich, auf der Gentz digital beruht. Ganz im Sinne von Forschungsdaten hat der Kölner Historiker und Politiker Günter Herterich akribisch Kopien, Mikrofilme und selbst erstellte Transkripte der Briefe Herterich zusammengetragen, wobei einige Transkripte bereits digital auf Disketten vorlagen. Der Anspruch des Projektes, die Briefe umfangreich erschlossen und durchsuchbar der Öffentlichkeit dauerhaft zur Verfügung zu stellen, ist ein Beispiel für Umsetzung der FAIR-Prinzipien bei der Archivierung. Forschende erhalten dadurch Zugang zur Nachnutzung in ihrem eigenen Forschungsprojekt, während die interessierte Öffentlichkeit im Sinne der Transparenz des Open-Science-Gedankens ebenfalls profitiert. Durch die detaillierte Erschließung und öffentlich Bereitstellung sind die Daten Findable und Accesible, die Inhalte können im Sinne der Interoperabilität als JSON exportiert werden und damit an anderer Stelle weitergenutzt werden, diese Reusability wird außerdem durch die Lizenzierung unter CC-Lizenz gewährleistet. Die Tatsache, dass 2022 ein Wechsel der Präsentationsplattform verbunden mit einer Übertragung der Daten in eine neue Datenbank im Backend stattgefunden hat, zeigt die Herausforderung der langfristigen Bereitstellung von Daten im Digitalen, die proaktive Arbeit erfordert4 (siehe unter: https://gentz-digital.ub.uni-koeln.de/portal/info/editorial.html?l=de; https://gentz-digital.ub.uni-koeln.de/portal/info/historie.html?l=de#info_sammlung).
Diskussion
Unbestreitbar hat durch den ‘Siegeszug’ der Digitalisierung die ‘digitale Revolution’ auch die Geschichtswissenschaft erfasst. ‘Digital Humanities’ und ‘Digital History’ sind hier Schlagworte, die die Veränderung des Fachgebiets aufzeigen, wobei zwischen einer eher technischen Digitalisierung - Lesen einer Archivquelle online statt vor Ort - und einer methodischen - Nutzung von z. B. datengetriebenen Analysetechniken - zu unterscheiden ist. Durch den verstärkten Einsatz digitaler Tools, Techniken und Methoden nimmt das Bewusstsein für die Notwendigkeit eines digitalen Forschungsdatenmanagements in der Geschichtswissenschaft zu, um die Potenziale, die in der Digitalisierung stecken, auch nutzen zu können.
Forschungsdaten, die gemäß dem Open-Science-Gedanken unter Beachtung der FAIR-Prinzipien bereitgestellt wurden, bieten nicht nur für das eigene Forschungsvorhaben Vorteile, da sie im Sinne der Nachnutzung'Eine Nachnutzung, oftmals auch Sekundärnutzung genannt, befragt bereits erhobene und veröffentlichte Forschungsdatensätze erneut mit dem Ziel, andere Erkenntnisse, möglicherweise aus einer neuen oder unterschiedlichen Perspektive, zu erhalten. Die Aufbereitung von Forschungsdaten für eine Nachnutzung erfordert einen erheblich höheren Anonymisierungs-, Aufbereitungs- und Dokumentationsaufwand als die bloße Archivierung im Sinne von Datenspeicherung.' (Data Affairs, Glossar) Weiterlesen für nachfolgende Erkenntnisinteressen verwendet werden können. Es handelt sich dabei um keinen neuen Ansatz, sondern letztlich um die konsequente Fortführung der Tradition in historisch arbeitenden Disziplinen, Quellen aus beispielsweise kritischen Editionen für das eigene Vorhaben zu nutzen. Durch die neu zugewiesene Bedeutung von Datenpublikationen ist ein weiteres Feld entstanden, das genutzt werden kann, um die eigene Reputation in der Fachgemeinschaft durch Publikation hochwertiger Forschungsdaten zu steigern. Was also traditionell oft die Veröffentlichung von transkribierten Quellen als Anhang einer Publikation war, erhält in Form der Datenpublikation einen höheren und sichtbareren Reputationswert.
Ein systematisches Forschungsdatenmanagement begleitet den gesamten Forschungsprozess und ermöglicht es, das Projekt auch bei kritischen Ereignissen – etwa versehentlich gelöschten Dateien, zerstörten Datenträgern oder Krankheit des Forschenden – weiterzuführen. Durch regelmäßige Backups werden Datenverluste verhindert, und eine lückenlose Dokumentation erleichtert es Vertretungen, sich schnell in das Projekt einzuarbeiten.
Ebenso wird die Einhaltung rechtlicher und ggf. ethischer Vorgaben unterstützt. Es handelt sich dabei um Tätigkeiten, die grundsätzlich auch im Analogen bereits notwendig waren, unter dem Schlagwort FDM für den digitalisierten Prozess aber einen neuen Namen und eine gewisse Standardisierung erfahren haben. Methoden wie ein Datenmanagementplan (DMP)'Ein Datenmanagementplan (DMP) beschreibt und dokumentiert den Umgang mit den Forschungsdaten und Forschungsmaterialien einer Forschung während und nach der Projektlaufzeit. Im DMP wird festgehalten, wie die Daten und Materialien entstehen, aufbereitet, gespeichert, organisiert, veröffentlicht, archiviert und ggf. geteilt werden. Zudem werden im DMP Verantwortlichkeiten und Rechte geregelt. Als 'living document' (also ein dynamisches Dokument, das sich fortlaufend in Bearbeitung und Veränderung befindet) wird der DMP im Laufe des Projektes regelmäßig geprüft und bei Bedarf angepasst.' (Data Affairs, Glossar) Weiterlesen helfen, den Überblick über die das Forschungsvorhaben begleitenden Tätigkeiten zu behalten und sie zu dokumentieren. Durch einen DMP kann die Arbeitsbelastung reduziert werden, weil immer wiederkehrende FDM-Aktivitäten in Forschungsprojekten (z. B. Backup, Dokumentation) klar definiert sind, denn diese Routinen müssen nicht für jedes weitere Forschungsvorhaben erneut überlegt werden.
Dies kann jedoch nicht darüber hinwegtäuschen, dass unter dem Oberbegriff FDM eine Vielzahl unterschiedlicher Aspekte vereint werden, die durchaus kritisch hinterfragt werden müssen. Schon die durch den Forschungsdatenlebenszyklus implizierten Prinzipien von Open Science sind aus sowohl praktischen als auch wissenschaftstheoretischen Überlegungen heraus nicht zwingend für alle Beteiligten positiv. Wissenschaft ist seit jeher zwar durch Offenheit immer aber auch durch Geheimhaltung geprägt (Levin und Leonelli 2017). Ebenso zwiespältig sind z. B. Datenmanagementpläne zu sehen. Als eine Form von Checkliste können sie eine hilfreiche Unterstützung sein, jedoch können sie als verpflichtendes Dokument eher zu einer weiteren Form von Bürokratie beitragen, deren gesamtgesellschaftliches Überborden immer mehr in der Kritik steht (Buschmann 2023).
Gerade bei der traditionellen hermeneutische Analyse von Primärquellen, auch wenn diese digital eingesehen werden, sollte in Betracht gezogen werden, dass das Teilen der dabei entstandenen ‘Forschungsdaten’ durch das Veröffentlichen kritischer Editionen oder des Abdruckens von Quellen im Rahmen von Publikationen auch ohne FAIR-Prinzipien bisher ganz gut funktioniert hat. Zudem bleibt noch die Frage offen, inwiefern Wissenschaftler*innen tatsächlich persönlich von einem Zugänglichmachen ihrer Daten profitieren (Wood und Gürlich 2025).
Der versprochene Reputationsgewinn und die Möglichkeit, selbst Daten anderer nachzunutzen, sind zunächst vage Zukunftsversprechen, die erst einmal einem erhöhtem Arbeitsaufwand durch die Datenpublikation in der Gegenwart gegenüberstehen.
Endnoten
- 1Siehe unter: https://dhmuseum.uni-trier.de/node/463
- 2
- 3
- 4
Literatur und Quellenangaben
Buschmann, Marco. 2023. „Überbordende Bürokratie legt die Axt an die Demokratie“. Bundesministerium der Justiz. Zuletzt aufgerufen am 28. Januar 2026. https://www.bmjv.de/SharedDocs/Meldungen/DE/2023/1007_FAZ_Entbuerokratisierung.html
Deutsche Forschungsgemeinschaft (DFG). 2022. Leitlinien zur Sicherung guter wissenschaftlicher Praxis. Kodex. Zenodo. https://doi.org/10.5281/zenodo.6472827
Directorate-General for Research and Innovation (European Commission). 2021. Horizon Europe, open science. Early knowledge and data sharing, and open collaboration. Luxemburg: Publications Office of the European Union. https://data.europa.eu/doi/10.2777/18252
Force11. The Future of Research Communications and e-scholarship. 2021. „The FAIR Data Principles“. Zuletzt aufgerufen am 22. Januar 2026. https://force11.org/info/the-fair-data-principles/
Forschungsdaten.info. 2024b. „Der Datenlebenszyklus“. Zuletzt aufgerufen am 22. Januar 2026. https://forschungsdaten.info/themen/informieren-und-planen/datenlebenszyklus/
Heldt, Camilla und Birgitt Röttger-Rössler. 2023. „Einführung in das Forschungsdatenmanagement“. Data Affairs. Datenmanagement in der ethnografischen Forschung. SFB 1171 & Center für Digitale Systeme, Freie Universität Berlin. https://data-affairs.affective-societies.de/artikel/einfuehrung-forschungsdatenmanagement/
Levin, Nadine, und Sabina Leonelli. 2017. „How Does One „Open“ Science? Questions of Value in Biological Research“. Science, Technology & Human Values 42 (2):280–305. doi:10.1177/0162243916672071
Rat für Sozial- und Wirtschaftsdaten (RatSWD). 2023. „Forschungsdatenmanagement in kleinen Forschungsprojekten – Eine Handreichung für die Praxis.“ RatSWD Output, 8(6). doi:10.17620/02671.72.
Rumpel, Hubert. 1964. „Gentz, Friedrich“. Neue Deutsche Biographie 6: 190-93 [Online-Version]. Zuletzt aufgerufen am 22. Januar 2026. https://www.deutsche-biographie.de/pnd118538489.html#ndbcontent
Sieminska, Paulina H. 2019. A FAIRy tale graphics (1.0.0). Zenodo. doi:10.5281/zenodo.3267168
Wood, John, und Yannis Gürlich. 2025. 4Memory Problem Stories. Zenodo. doi:10.5281/zenodo.17077527
Weitere Literatur
Blaney, Jonathan. 2021. Doing Digital History: A Beginner’s Guide to Working with Text As Data. Manchester: Manchester University Press.
Cremer, Fabian, Silvia Daniel, Marina Lemaire, Katrin Moeller, Matthias Razum, und Arnošt Štanzel. 2021. „Data meets history: A research data management strategy for the historically oriented humanities“. In Cultural Sovereignty beyond the Modern State, herausgegeben von Gregor Feindt, Bernhard Gissibl, und Johannes Paulmann: 155–78. Berlin, Boston: De Gruyter. https://doi.org/10.1515/9783110679151-009.
Forschungsdaten.Info. 2025. „Richtlinien und Policies: Wozu werden diese benötigt?“. Zuletzt aufgerufen am 23. Januar 2026. https://forschungsdaten.info/themen/ethik-und-gute-wissenschaftliche-praxis/leitlinien-und-policies/
Forschungsdaten.info. 2023f. „Was ist Forschungsdatenmanagement?“. Zuletzt aufgerufen am 23. Januar 2026. https://forschungsdaten.info/themen/informieren-und-planen/was-ist-forschungsdatenmanagement/
König, Mareike. 2023. „Die digitale Transformation in den Geschichtswissenschaften“. In Digital Humanities in den Geschichtswissenschaften, herausgegeben von Christina Antenhofer, Christoph Kühberger, und Arno Strohmeyer, 19–42. Stuttgart: utb. https://doi.org/10.36198/9783838561165
Lemaire, Marina. 2018. „Vereinbarkeit von Forschungsprozess und Datenmanagement in den Geisteswissenschaften“. o-bib. Das offene Bibliotheksjournal 5 (4): 237-47. doi:10.5282/O-BIB/2018H4S237-247
Queckbörner, Boris. 2019. Forschungsdaten und Forschungsdatenmanagement in der Geschichtswissenschaft. Gegenwärtige Praxis und Perspektiven am Beispiel ausgewählter Sonderforschungsbereiche. Berlin: Institut für Bibliotheks- und Informationswissenschaft der Humboldt-Universität zu Berlin. doi:10.18452/20460
Zitierweise
Benz, Jacob und Voigt, Anne. 2026. „Einführung in das Forschungsdatenmanagement“. HISTOFOX. Das Informations-, Lern- und Lehrportal für Datenkompetenzen in den historisch arbeitenden Disziplinen. NFDI4Memory und Freie Universität Berlin. https://histofox.4memory-dataliteracy.de/artikel/einfuehrung-forschungsdatenmanagement/