Archivierung
Definition
„Archivierung ist die sichere Aufbewahrung bewusst ausgewählter Forschungsdaten einschließlich ihrer Metadaten und weiterer Dokumentation für eine definierte Aufbewahrungsfrist. Das Ziel ist, sie über das Projektende hinaus zugänglich zu halten, ihre Nachnutzung zu ermöglichen, ihre Integrität zu gewährleisten und die Einhaltung guter wissenschaftlicher Praxis nachzuweisen.“
(Glossar Lernzielmatrix 2025)
Einführung
Das Stichwort „Archivierung“ ist untrennbar mit dem Bild des Archivs verknüpft. Gerade für Forschende aus historisch arbeitenden Disziplinen ist der Begriff Archiv zudem mit einer Vielzahl an weiteren Gedanken verbunden, von Findbüchern über den physischen Aufenthalt im Gebäude des Archivs bis hin zur Unterstützung bei der Arbeit durch die Fachexpertise von Archivar*innen. Hinzugekommen ist mittlerweile auch der digitale Zugriff auf Archivgut, verbunden mit der Frage, wie genuin digitale Quellen - z. B. Webseiten, digitale Akten - zukunftsfähig archiviert werden können.
Im Kontext des Forschungsdatenmanagements ist der Begriff jedoch etwas anders konnotiert. Hier steht die Aufbewahrung digitaler bzw. digitalisierter Forschungsdaten im Fokus. Die zu archivierenden Daten werden durch die Projekte selbstständig ausgewählt und mit den notwendigen Metadaten'Metadaten sind Beschreibungen von Forschungsdaten (Daten über Daten) und geben inhaltliche und strukturierte Informationen zum Forschungskontext, dem methodischen und analytischen Verfahren, sowie über das jeweilige Forschungsteam, das die Daten generiert. Sie lassen sich unterscheiden in bibliographische, administrative, prozessuale und deskriptive Metadaten und werden beispielsweise in Form von Templates, ReadMe-Dateien oder Data Curation Profiles verfasst. Metadaten werden begleitend zu den Forschungsdaten selbst publiziert und gelten insbesondere in Online-Repositorien und Forschungsdatenzentren als unverzichtbar für das Nachvollziehen und Verstehen von Datensätzen durch Dritte. Auch erleichtern Metadaten die Auffindbarkeit und Maschinenlesbarkeit von Daten und sind somit Teil der FAIR-Prinzipien und der guten wissenschaftlichen Praxis.' (Data Affairs, Glossar) Weiterlesen versehen. Die Aufbewahrungsfrist ist dabei z. B. durch institutionelle Regeln vorgegeben und beträgt oft zehn Jahre, wie in den Richtlinien der DFG zur guten wissenschaftlichen Praxis'Die gute wissenschaftliche Praxis (GWP) bildet einen standardisierten Kodex, der als Regelwerk in den Leitlinien der Deutschen Forschungsgemeinschaft (DFG) verankert ist. Die Leitlinien verweisen auf die ethische Verpflichtung jedes/jeder Forschenden, verantwortungsvoll, ehrlich und respektvoll vorzugehen, auch um das allgemeine Vertrauen in Forschung und Wissenschaft zu stärken. Sie können als Orientierung im Rahmen wissenschaftlicher Arbeitsprozesse geltend gemacht werden.' (Data Affairs, Glossar) Weiterlesen gefordert (Deutsche Forschungsgemeinschaft 2022, 22). Zu beachten ist ebenfalls, dass beispielsweise bestimmte Zugriffsbeschränkungen'In Archiven oder Repositorien regeln Zugriffsrechte, welche Personen in welchem Umfang Zugang und Einsicht in Datenmaterial zur Nachnutzung bekommen. I. d. R. wird unterschieden zwischen einem Weiterlesen eingehalten werden.
Motivation
Grundsätzlich kann aus den unterschiedlichsten Gründen archiviert werden. Im geschäftlichen und behördlichen Kontext spielen dabei oft gesetzliche Dokumentations- und Abgabepflichten (Stichwort Archivgesetze) eine Rolle.
Gleiches gilt für die Archivierung von Forschungsdaten, hier greifen ebenfalls oft institutionelle oder andere Vorgaben. Insbesondere bei Projekten mit Unterstützung durch Forschungsförderer'Förderinstitutionen sind all jene Einrichtungen, die wissenschaftliche Forschung finanziell fördern, also Stiftungen, Vereine oder andere Organisationen. Die meisten dieser Einrichtungen im internationalen Raum haben dabei Richtlinien für das Forschungsdatenmanagement (FDM) von Forschungsprojekten eingeführt, d. h. eine mögliche finanzielle Förderung ist an Bedingungen und Forderungen zum Umgang mit Forschungsdaten geknüpft. Zu den bekanntesten Förderinstitutionen im deutschsprachigen Raum gehören das Bundesministerium für Bildung und Forschung (BMBF) selbst, die Bildungs- und Wissenschaftsministerien der Bundesländer, die Deutsche Forschungsgemeinschaft (DFG), die Volkswagenstiftung oder der Österreichische Wissenschaftsfonds (FWF) sowie der Schweizer Nationalfonds (SNF).' (Data Affairs, Glossar) Weiterlesen wie die Deutsche Forschungsgemeinschaft kommt die Sicherung der guten wissenschaftlichen Praxis'Die gute wissenschaftliche Praxis (GWP) bildet einen standardisierten Kodex, der als Regelwerk in den Leitlinien der Deutschen Forschungsgemeinschaft (DFG) verankert ist. Die Leitlinien verweisen auf die ethische Verpflichtung jedes/jeder Forschenden, verantwortungsvoll, ehrlich und respektvoll vorzugehen, auch um das allgemeine Vertrauen in Forschung und Wissenschaft zu stärken. Sie können als Orientierung im Rahmen wissenschaftlicher Arbeitsprozesse geltend gemacht werden.' (Data Affairs, Glossar) Weiterlesen (GWP) hinzu, der sich alle antragsberechtigten Einrichtungen verpflichtet haben. Die GWP fordert die Archivierung von Daten zur Herstellung von Transparenz hinsichtlich der Entstehung von Forschungsergebnissen. Die Idee dahinter ist die Reproduzierbarkeit, d. h. dass Dritte anhand der einsehbaren Daten die Schlussfolgerungen unabhängig überprüfen und nachvollziehen können (Deutsche Forschungsgemeinschaft 2022, 22).
Neben diesen Vorgaben können Forschende auch eine intrinsische Motivation haben, ihre Daten zu archivieren. Gerade in den historisch arbeitenden Disziplinen ist das Bewusstsein hinsichtlich der Notwendigkeit von Archivierung hoch, sind doch nicht überlieferte Quellen oft ein Ärgernis bei der eigenen Forschungsarbeit. Hier die Quellenlage für nachfolgende Generationen von Forscher*innen zu verbessern, kann zur sorgfältigen Archivierung der eigenen Forschungsdaten motivieren. Auch wenn die eigenen Materialien vielleicht niemals die Bekanntheit eines Zettelkastens von Niklas Luhmann erlangen werden (Schmidt 2025), so können sie doch auf vielfältige Weise unter neuen Fragestellungen in Zukunft untersucht werden, nicht zuletzt aus wissenschaftsgeschichtlicher Perspektive.
Eine eigenständige Archivierung von Forschungsdaten als Einzellösung ist in der Regel nicht zielführend. Denn Einzelpersonen oder Projektgruppen können die langfristig erforderlichen technischen Maßnahmen – etwa redundante und geografisch verteilte Backups, regelmäßige Integritätsprüfungen (Checksums), sichere Zugriffskontrollen oder die dauerhafte Bereitstellung stabiler Identifikatoren – kaum zuverlässig gewährleisten. Professionelle Datenarchive verfügen dagegen über die notwendige Infrastruktur, Expertise und organisatorische Stabilität, um Daten über viele Jahre hinweg sicher und nachvollziehbar zu erhalten. Hinzu kommt, dass Forschungsdaten im Sinne der guten wissenschaftlichen Praxis personenunabhängig verfügbar sein müssen: Wenn Fragen zu Forschungsergebnissen auftreten, darf der Zugang zu den zugrunde liegenden Daten nicht davon abhängen, ob einzelne Projektmitglieder noch erreichbar sind oder private Speichersysteme weiterhin funktionieren. Eine Archivierung in einem institutionell getragenen Datenzentrum stellt sicher, dass Daten langfristig auffindbar, überprüfbar und verantwortungsvoll verwaltet bleiben.
Vorgehen
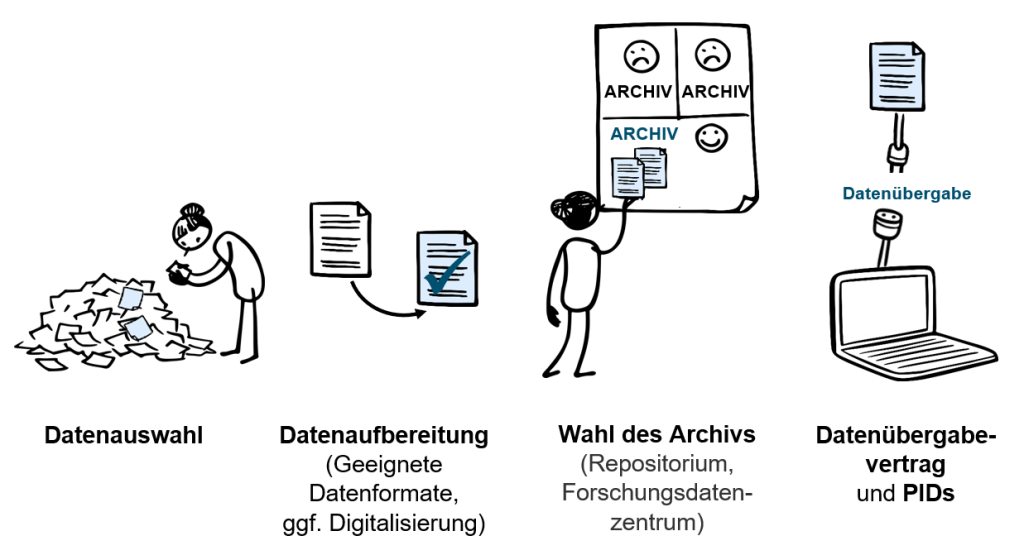
Grafik: Archivierung, Anne Voigt mit CoCoMaterial, 2025, lizenziert unter CC BY-SA 4.0
Datenauswahl
Jeder Archivierungsvorgang erfordert die Bewertung der zu archivierenden Dokumente und das Aussortieren derjenigen, die nicht übernommen werden. Auch bei der Archivierung der eigenen Forschungsunterlagen muss dieser Vorgang stattfinden.
Der zunächst eventuell naheliegende Gedanke, schlicht alle einem Forschungsvorhaben zugehörige Unterlagen zu archivieren, muss bei näherem Hinsehen relativiert werden. Oft ist es unmöglich oder unpraktisch, komplette Materialkorpora einer Forschung, bspw. inklusive handschriftlicher Notizen, zu archivieren. Gerade, da im Kontext des aktuellen Forschungsdatenmanagements die digitale Archivierung gemeint ist, wäre in vielen Fällen die zuvor notwendige Digitalisierung handschriftlicher Materialien ein unverhältnismäßig hoher Aufwand. Während es im Digitalen zwar im Vergleich zum traditionellen Archivieren in aller Regel keine physischen Platzprobleme gibt, ist die Datenmenge dennoch zu beachten, v. a. auch hinsichtlich der ökologischen Nachhaltigkeit, sollte Datensparsamkeit ein leitendes Kriterium bei der Auswahl der zu archivierenden Daten sein.
Praktisch sind daher bei der Auswahl der zu archivierenden Daten einige Überlegungen zu treffen:
- Welche Materialien sind archivwürdig? Nicht jeder Versionsstand eines internen Zwischenberichts ist für die Nachvollziehbarkeit von Forschungsergebnissen relevant. Sämtliche Unterlagen zu archivieren, würde nur zur Datenflut beitragen.
- Welche Materialien können mit vertretbarem Aufwand archiviert werden? Insbesondere beim hybriden Arbeiten sollte auch für analoge Unterlagen, bspw. handschriftliche Notizen, geprüft werden, ob überhaupt Kapazitäten vorhanden sind, diese im Universitätsarchiv zu archivieren, ggf. gar zu digitalisieren. Werden analoge Forschungsdaten archiviert, sollte ihr Standort bei den digitalen Daten ebenfalls vermerkt werden.
- Wie ist mit sensiblen Daten'Einen eigenen Teilbereich innerhalb der personenbezogenen Daten bilden die sog. besonderen Kategorien personenbezogener Daten. Ihre Definition geht auf den EU-DSGVO Artikel 9 Abs. 1, 2016 zurück, der besagt, dass es sich hierbei um Angaben über Weiterlesen umzugehen? Hierbei handelt es sich vor allem um personenbezogene Daten, die z. B. im Kontext von Interviews bei Oral-History-Projekten verarbeitet werden. Wenn keine Rechte zur Archivierung eingeräumt wurden, können die Daten nicht archiviert werden. Bei Befragungen und Interviews muss daher die zuvor einzuholende Einverständniserklärung'Informierte Einwilligung (informed consent) meint die Zustimmung der Forschungsteilnehmenden zur Teilnahme an einem Forschungsvorhaben auf der Basis umfangreicher und verständlicher Informationen. Die Ausgestaltung einer informierten Einwilligung muss dabei sowohl ethische Grundsätze als auch datenschutzrechtliche Anforderungen adressieren.' (Data Affairs, Glossar) Weiterlesen einen Hinweis auf die Archivierung enthalten. In jedem Fall ist bei der Archivierung solcher Materialien eine sorgfältige Auswahl des Archivs notwendig.
- Handelt es sich beim zu archivierenden Material auch um urheberrechtlich'Das Urheberrecht (UrhG) schützt bestimmte geistige Schöpfungen (Werke) und Leistungen. Unter Werke fallen Sprachwerke, Lichtbild-, Film- und Musikwerke sowie Darstellungen wissenschaftlicher oder technischer Art, wie Zeichnungen, Pläne, Karten, Skizzen, Tabellen und plastische Darstellungen (Gesetz über Urheberrecht und verwandte Schutzrechte 2021, §2). Die künstlerischen, wissenschaftlichen Leistungen von Personen oder die getätigte Investition gelten dagegen als schützenswerte Leistungen (Leistungsschutzrecht). Der*die Urheber*in ist berechtigt, das Werk zu veröffentlichen und zu verwerten.' (Data Affairs, Glossar) Weiterlesen oder anderweitig geschütztes Material? Dann müssen ggf. die Nutzungsrechte an den Daten zuvor eingeholt und dann dokumentiert sein (siehe auch Artikel zum Urheberrecht).
Um den Arbeitsaufwand am Ende des Forschungsvorhabens zu reduzieren, ist es daher sinnvoll, die notwendige Archivierung bereits in der Planungsphase mitzudenken. So können schon während der Projektdurchführung Dateien zur Archivierung markiert werden. Noch viel wichtiger ist jedoch, bereits beim Erstellen der Daten eine Dokumentation zu pflegen, da ohne eine solche die spätere Nachvollziehbarkeit erschwert wird.1Datendokumentation dient dazu, zu beschreiben, wie Daten aufgebaut sind, wie sie erhoben wurden und zu welchem Zweck sie ursprünglich verwendet wurden. Bei digitalisierten Schriftquellen wäre beispielsweise zu dokumentieren, mit welchen Methoden diese digitalisiert wurden, an welchem Standort sich die Originale befinden und ob anschließend Methoden wie OCROptical Character Recognition (OCR) bezeichnet die automatische Texterkennung von gedruckten oder maschinengeschriebenen Werken. Der Scan des Durckwerks wird maschinell erfasst und in einen elektronischen Text umgeformt. Die Automatisierung beruht auf dem Erkennen von Mustern und Gesetzmäßigkeiten, dem so genannten maschinellen Lernen. Weiterlesen angewendet wurden und ob es dabei eine Nachkorrektur gab. Welche Daten archiviert und wie diese dafür beschrieben werden sollen, kann im Datenmanagementplan (vgl. Artikel Datenmanagementplan) festgehalten werden.
Archive, Repositorien und Forschungsdatenzentren (FDZ)
Forschungsdaten können auf unterschiedliche Weise und damit auch an unterschiedlichen Orten archiviert werden. Die folgende Tabelle gibt einen Überblick über die unterschiedlichen Formate, die eine Archivierung von Forschungsdaten anbieten. Zu beachten ist dabei, dass der Übergang zwischen einer reinen Archivierung und einer aktiven Bereitstellung zur Nachnutzung fließend sein kann. Grundsätzlich kann festgehalten werden, dass bei einem Ziel der aktiven Nachnutzung auch der Aufbereitungsaufwand steigt, da Daten nicht nur passiv archiviert, sondern aktiv durch die Forschungsgemeinschaft genutzt werden sollen.
| Merkmal | Forschungsdaten-repositorium | Forschungsdaten-zentrum | Datenarchiv |
| Hauptzweck | Veröffentlichung, Nachnutzung | Kuratierte Bereitstellung für Forschung | Langzeitbewahrung, Sicherung |
| Zugang | Häufig offen | Reguliert, teils restriktiv | Unterschiedlich – oft passiv zugänglich |
| Kuratierung | Gering bis mittel | Hoch | Mittel bis hoch |
| Betreuung | Minimal | Intensive Beratung | Archivfachlich, nicht primär forschungsgeleitet |
| Technischer Fokus | Speicherplattform | Dateninfrastruktur + Support | Erhaltungsstrategien, Formaterhalt |
| Relevanz für Nutzung | Hoch (Zweck: Nachnutzung) | Hoch (Zweck: Sekundärnutzung) | Niedrig bis mittel (Zweck: Sicherung) |
Für die historisch arbeitenden Disziplinen gibt es noch keine feststehenden Forschungsdatenzentren und Repositorien, die von allen uneingeschränkt für die alleinige Archivierung genutzt werden können, deshalb ist das Archiv oder Repositorium der eigenen Institution in der Regel die erste Anlaufstelle. Viele Hochschulen und Universitäten verfügen über ein solches Archiv oder sind dabei ein solches aufzubauen und stellen qualifiziertes Personal bereit, das beraten bei der Datenauswahl und -übergabe kann.
Für eine Archivierung geeignete Datenformate
Die Leitlinien der guten wissenschaftlichen Praxis sehen mindestens 10 Jahre Aufbewahrungsfrist vor (Deutsche Forschungsgemeinschaft 2022, 22). Neben der Sicherstellung der Interpretierbarkeit der Daten durch eine begleitende Dokumentation sowie Metadaten, ist es gemäß den FAIR-Prinzipien'Die FAIR-Prinzipien wurden 2016 erstmals von der FORCE 11-Community (The Future of Research Communication and e-Scholarship) entwickelt. FORCE11 ist eine Gemeinschaft von Wissenschaftlern, Bibliothekaren, Archivaren, Verlegern und Forschungsförderern, die durch den effektiven Einsatz von Informationstechnologie einen Wandel in der modernen wissenschaftlichen Kommunikation herbeiführen und so eine verbesserte Wissenserstellung und -weitergabe unterstützen will. Das primäre Ziel liegt in der transparenten und offenen Darlegung wissenschaftlicher Erkenntnisprozesse. Demnach sollten Daten online findable (auffindbar), accessible (zugänglich), interoperable (kompatibel) und reusable (wiederverwendbar) abgelegt und strukturiert sein. Ziel ist es, Daten langfristig aufzubewahren und im Sinne der Open Science und des Data Sharing für eine Nachnutzung durch Dritte bereitzustellen. Genaue Definitionen der FORCE11 selbst können auf der Website nachgelesen werden siehe: https://force11.org/info/the-fair-data-principles/. Die FAIR-Prinzipien berücksichtigen ethische Aspekte der Weitergabe von Daten in sozialwissenschaftlichen Kontexten nicht hinreichend, weshalb sie um die CARE-Prinzipien ergänzt wurden.' (Data Affairs, Glossar) Weiterlesen wichtig, auch deren Nutzbarkeit durch geeignete DateiformateDie Begriffe Dateityp und Dateiformat werden meist synonym verwendet, bezeichnen jedoch verschiedene Dinge.'Das Dateiformat ist die spezifische technische Implementierung einer Datei, d. h. wie die Daten gespeichert, repräsentiert und interpretiert oder verarbeitet werden. In der Regel sind Dateiformate an Dateierweiterungen, zum Beispiel PNG oder TIFF, zu erkennen.' (Lernzielmatrix Glossar 2025) Weiterlesen zu gewährleisten. Für eine Archivierung weniger geeignet sind Formate, die für ihre Verarbeitung eine proprietäre'Proprietäre Dateiformate sind Dateiformate, die sich nicht oder nur mit Schwierigkeiten von Dritten öffnen bzw. lesen lassen, da sie z. B. lizenzrechtlich oder durch Patente geschützt sind. Meist wird dafür spezielle (kostenpflichtige) Software benötigt (Wikipedia 2023). Beispiele hierfür sind z. B. das Wordformat .docx oder das Adobe Photoshop-Format .psd.' (Data Affairs, Glossar) Weiterlesen meist kostenpflichtige Software wie Microsoft Office, MaxQDA oder Photoshop benötigen. Wird mit einer solchen Software in einem Forschungsvorhaben gearbeitet, sollten die Daten für die Archivierung zusätzlich in geeignetere offene Dateiformate konvertiert werden. Offene Dateiformate sind dadurch gekennzeichnet, dass ihr Aufbau frei zugänglich dokumentiert ist, bestenfalls sogar standardisiert mittels beispielsweise einer ISO-Norm. Auch darf kein Unternehmen Patente an dem Dateiformat halten bzw. müssen diese Patente so für die Allgemeinheit freigeben sein, dass für die Implementierung eines Formats keine Lizenzgebühren anfallen. Dadurch können Daten, die in einem solchen offenen Format gespeichert wurden, auch dann noch gelesen werden, wenn die ursprüngliche Software nicht mehr existiert, da durch Dritte ein neues Programm zum Öffnen der Dokumente geschrieben werden kann.2Dies ist zumindest die theoretische Überlegung hinter der Forderung nach Nutzung offener Dateiformate. Praktisch sind moderne Dateiformate so komplex, dass selbst ISO-genormte Dateiformate nicht einheitlich zu implementieren sind. Verwiesen sei hier auf die beiden ISO-standardisierten Office-Formate “Open Document Format” von LibreOffice und “Office Open XML” von Microsoft Office. Beide Programme können Dokumente im Format des jeweils anderen öffnen und schreiben, komplexe Formatierungen werden dabei jedoch oft beschädigt. Für eine Archivierung ist ebenfalls wichtig, dass die Dateien verlustfrei gespeichert werden. Insbesondere Audio- und Bildformate nutzen oft eine verlustbehaftete Komprimierung zur Reduzierung der Dateigröße. Dadurch können jedoch beispielsweise Bilddetails verloren gehen, die für eine zukünftige Analyse relevant sein könnten.
Meist kann eine Konvertierung direkt in der entsprechenden Software beim Speichern oder unter Export vorgenommen werden. Auch die Dateien im Originalformat müssen archiviert werden, da bei der Konvertierung oft ein Informationsverlust eintritt.
Tabelle: Für eine Archivierung empfohlene Dateiformate (Forschungsdatendienst OstData 2019)
| Dateiformate für | Empfohlenes Dateiformat |
| Bilder | .tiff/.tif |
| Vektorgrafik | .svg/.svgz |
| Texte | Statische Texte: .pfd (in der ISO-Standardform PDF/A) Strukturierte Texte: .xml (auf XML basierende Formate wie .tei, .dta) Text: .rtf, .txt (als UTF-8-codiert) Text (Office): .odt/.fodt Text (Publikation plus Formeln): .tex |
| Tabellen/Datenbanken | Tabellen: .csv.ods/.fods Statistik-Softwareformate/Quantitative Daten in Tabellen mit umfangreichen Metadaten: SPSS portable format (.por)STATA (*.dta)R (*.R)SAS Transport (*.sas) Weit verbreitete (proprietäre) Formate von Statistikpaketen, wie z.B. SPSS: (*.sav), Stata (*.dta) Relationale Datenbanken:SIARD |
| Audio | .wav; .flac |
| Video | .mkv; mp4; .mxf |
| Geodaten | ESRI Shapefile (essential): .shp, .shx, .dbf ; optional: .prj, .sbx, .sbn) GeoTIFF: .kml, .csv |
| Software | als Quellcode (unkompiliert) und Dokumentation |
Eine weitere Herausforderung besteht bei der Archivierung von Software. Projekte, die als Teil ihres Forschungsvorhabens digitale (Analyse)methoden benutzen, verwenden oft Software nicht nur zur Erzeugung von Dateien, sondern als integralen Bestandteil der Analyse selbst, z. B. bei der automatischen Erkennung von Themen in Dokumenten (Topic Modeling'Das Topic Modeling ist ein statistisches, auf Wahrscheinlichkeitsrechnung basierendes, Verfahren zur thematischen Exploration größerer Textsammlungen. Das Verfahren erzeugt 'Topics' zur Abbildung häufig gemeinsam vorkommender Wörter in einem Text.' (forTEXT) Weiterlesen). Hierzu wird vielfach eigener Quellcode geschrieben, der auf weitere Programmbibliotheken zurückgreift. Damit die mit dieser Software erzeugten Ergebnisse nachvollzogen und nachgenutzt werden können, ist eine Archivierung der Software selbst notwendig. Dieser Software-Quellcode muss ebenfalls umfangreich dokumentiert archiviert werden. Abhängigkeiten von Bibliotheken und Entwicklungsumgebungen müssen so genau wie möglich spezifiziert werden.
Anwendungsbeispiele
Beispiel: Auszug aus einem Interview mit Stefan Schmunk zum Bomber's Baedeker, 2025
als Audio
Audio: Interviewauszug Stefan Schmunk zum Bomber's Baedeker, 2025, lizenziert unter CC BY-NC-ND 4.0
als Transkript
Jacob B.: Lieber Stefan, vielen Dank, dass du dir Zeit genommen hast für unser Interview, auch zum Thema Digitales Arbeiten in den Geschichtswissenschaften mit dem Fokus auf deinem Projekt Bomber's Baedeker. Es würde mich freuen, wenn du dich vielleicht kurz selbst vorstellen könntest.
Stefan Schmunk: Hi, mein Name ist Stefan Schmunk. Ich bin von Hause aus Historiker, Politologe und Informationswissenschaftler und bin hier an der Hochschule Darmstadt seit mittlerweile sieben Jahren, seit 2018 auf einer Professur für Informationswissenschaft und Bibliothekswissenschaften.
Jacob B.: Vielen Dank. Vielleicht gleich die erste Frage. Kannst du uns kurz dein Projekt vorstellen und auch sagen, was speziell der digitale Anteil daran war?
Stefan Schmunk: Wir haben vor, ja eigentlich vor der Pandemie, also vor sieben, acht Jahren per Zufall durch die Leiterin der wissenschaftlichen Bibliothek des Instituts für Europäische Geschichte in Mainz den Bomber's Baedeker entdeckt. Und in Deutschland ist das eine der wenigen Bibliotheken, die die beiden Bände noch im Original besitzen, aus dem Jahr 1944.
Und gemeinsam mit Thorsten Wübbener, dem Leiter der DH-Abteilung in Mainz, hatten wir uns überlegt, das ist so ein toller Bestand, der weltweit eigentlich gar nicht zugänglich ist digital, dass wir gemeinsam mit der Universitätsbibliothek der Uni Mainz diesen Baedeker digitalisiert haben und zugleich aber uns einfach gefragt haben - ich muss kurz ausholen an der Stelle, was ist überhaupt der Baedeker?
Bomber's Baedeker ist kein Reiseführer, wie der Name vielleicht nahelegen würde. Bomber’s Baedeker ist eine Aufstellung der Royal Air Force und des Foreign Office Großbritanniens während des Zweiten Weltkrieges über die zentralen strategischen Ziele für die Royal Air Force während des Zweiten Weltkrieges im Deutschen Reich. Ungefähr 400 Städte sind dort verzeichnet und diese Städte sind nicht nur verzeichnet als Namen oder auf einer Landkarte, sondern es gibt ganz konkrete Informationen darüber, welche Industriebetriebe in diesen Städten existierten.
Das Faszinierende aus der historischen Perspektive daran ist, dass die Alliierten, insbesondere Großbritannien, ganz viele Informationen über Deutschland hatten zu dem Zeitpunkt, weil die Brandversicherungsakten aus dem Deutschen Reich Mitte der 30er Jahre an britische Rückversicherungen gingen und dementsprechend man ganz genau wusste, wie die Hausstruktur in allen Städten und Dörfern des Deutschen Reiches waren, ob die Gebäude mit Ziegeln gebaut waren, ob es Fachwerk war, ob es Lehmbauten waren, wie die Dachstrukturen waren, ob es Holzaufbauten gab etc. Also eine faszinierende Informationsflut über die urbanen Zentren des Deutschen Reiches, gepaart mit den Straßen- und Ortsangaben von dort ansässigen Unternehmen. Das kombiniert mit Geheimdienstinformationen während des Zweiten Weltkrieges. Eine Reihe von Unternehmen gingen aufgrund des Bombenkriegs dann aus den Städten raus, wurden ausgelagert oder entwickelten sich. All das findet sich in diesem Bomber's Baedeker und deswegen ist es eben nicht als Reiseführer zu verstehen, sondern eigentlich aus einer wirtschaftspolitischen Perspektive echt faszinierend. Man hat den Überblick über den Stand des Wissens, was die Alliierten 1944 über das Deutsche Reich wussten und über die Industrie.
Das ist so ein für uns spannender Bestand gewesen, wo wir sagten, Digitalisierung reicht nicht aus. Da sind ganz viele Informationen drin von Straßennamen, von Unternehmensnamen, von Größenangaben oder eben auch von Produktionstypen, die dort hinterlegt sind, wo wir einfach sagten, naja, wir müssen es nicht nur digital erschließen, sondern auch auf eine gewisse Art und Weise eben auch maschinenlesbar und interpretierbar machen, weil so viel Substanz und Material einfach in einer Dichte drin steckt, die man in dieser Form eigentlich kaum findet, auch für die Epoche. Das vielleicht als kurzer, wirklich ganz kurzer Abriss dazu.
Jacob B.: Genau, aber das wäre nämlich auch so ein bisschen die Frage nach dem Mehrwert. Was war denn wirklich nur möglich, weil du eben digital gearbeitet hast, beziehungsweise welche Vorteile, sagen wir mal, von der wissenschaftlichen Erschließung haben sich daraus denn ergeben?
Stefan Schmunk: Klar, also das Problem bei Digitalisierung ist oftmals, dass wir eigentlich immer dann nur so digitale Repräsentationen des analogen Materials vorliegen haben. Und das ist dann, naja, ein PDF ist nichts anderes als eine kopierte Seite, bloß als Datei. Und der Mehrwert besteht genau darin, was ich eben schon beschrieben habe. Wir haben eben nicht nur ein PDF, nicht nur ein Bilddigitalisat vorliegen, sondern wir haben eigentlich den Text und die Inhalte ausgezeichnet. Das Spannende für uns eben auch aus einer Lehrperspektive, das war ein Lehrforschungsprojekt im ersten Schritt mit Studierenden an der Hochschule Darmstadt, wo wir sagten, naja, dann lasst uns doch mal bitte probieren, die OCR zu verbessern. Dann lasst uns mal bitte probieren, die Fehlerrate zu reduzieren. Und lasst uns im nächsten Schritt auch überlegen, wie können wir eigentlich maschinell auf einer Code-Basis, naja, eine Verbesserung des Qualitätsgrades herstellen.
Es sind unter anderem Geokoordinaten angegeben. Und dann ist vollkommen klar, wenn da eine Ziffer falsch ist, ist der Fehler ganz eklatant. Und man findet auf einmal nicht mehr Mannheim, was geografisch dann am Rhein liegt, sondern Mannheim ist Minsk. Und man hat durch den Zahlendreher eben eine komplett andere Geokoordinate an dieser Stelle. Und der Mehrwert, um auf deine Frage nochmal eingangs einzugehen, ist, dass eigentlich erst jetzt auch so eine richtige Interpretierbarkeit des Materials möglich ist, was im Vorfeld gar nicht machbar wäre, weil man müsste eigentlich Tage, Wochen, Monate, wenn nicht sogar Jahre über großen Plänen hängen, um all die Informationen einzutragen und einen Abgleich dann zu machen. Also insofern, das Digitale eigentlich als Tor in die Analyse überhaupt per se.
Jacob B.: Gab es eine Archivierungsstrategie speziell für dieses Projekt? Wie sah diese aus? Genannt sei auch die Archivierung im Sinne 10-jähriger Aufbewahrungsfrist zur Sicherung der guten wissenschaftlichen Praxis. Was habt ihr archiviert? Habt ihr auch Zwischenstände archiviert oder irgendwelche Projektnotizen, andere Sachen, die noch angefallen sind?
Stefan Schmunk: Das war für uns eine spannende Frage, weil es ja keinen guten Standard gibt. Ich weiß nicht, ob du einen guten Standard kennst, den man anwenden sollte.
Wir haben Versionen gespeichert. Oder vielleicht Step by Step. Im ersten Schritt sind wir bewusst eine Kooperation mit der Universitätsbibliothek in Mainz eingegangen. Weil wir gesagt haben, Universitätsbibliotheken haben einen öffentlichen, gesellschaftlichen und damit auch politischen Auftrag, Daten frei zugänglich zu halten und die entsprechende Infrastruktur dafür zu betreiben. Das heißt, die kompletten Bilddigitalisate finden sich dort. Das Original ist in der Bibliothek des Institut für europäische Geschichte weiterhin. Die Bilddigitalisate bei der UB der Uni Mainz. Und alle anderen Anreicherungen werden als Version dort mit angeboten. Wir haben zugleich den Code auf Git publiziert und veröffentlicht, haben eine Referenzierung über Zenodo, sodass dass das zugänglich ist, und haben auf Basis von diesen drei Repositorien unsere Publikationen dann auch veröffentlicht, wo auf persistente Identifier eben referenziert wird und all diejenigen, die sich dafür interessieren und die auch dann nachverfolgen wollen, mit welchen Daten wir zu welchen Schlüssen gekommen sind, können darauf zugreifen. Das finde ich, ist der große Vorteil.
Also ich denke, wir müssen mehr in Versionen denken. Wir müssen vor allem auch mehr daran oder darüber nachdenken, dass Forschung eigentlich nicht beendet sein kann und beendet wird dann zu einem gewissen Zeitpunkt, sondern dass dieses Fluide des Digitalen eigentlich auch dann in den Forschungsergebnissen Einklang findet.
Jacob B.: Das war also von Anfang an auch in dem Sinne gedacht, das so zur Verfügung zu stellen und zur Nachnutzbarkeit?
Stefan Schmunk: Das ja, aber wir wissen selber nicht, ob es der bestmögliche Weg ist. Also ich glaube, das wird sich nochmal zeigen, aber es war ein Weg, den wir halt sehr bewusst gegangen sind, Thorsten und ich, wo wir gesagt haben, okay, lasst uns das so publizieren, weil dann haben wir, glaube ich, auch einen guten Use-Case. Zugleich aber auch der Versuch für uns, zu erproben, wie man damit umgehen kann. Es ist aufwendig. Es ist einfach aufwendig, weil diese Publikation von Versionen, das ist halt nicht fire and forget und man ist damit zu Ende, sondern man muss durchaus überlegen, wann Zwischenstand eben auch Sinn macht.
Diskussion
Die Arbeit in Archiven und das Stützen auf darin aufbewahrte Unterlagen ist einer der zentralen Faktoren der Forschung in historisch arbeitenden Disziplinen. Bei der Archivierung der eigenen Forschungsdaten wird man selbst zum Quellenerzeugenden (Datengebenden). Es ist daher hilfreich, darüber nachzudenken, was man gerne selbst bei der Auswertung von Archivmaterialien vorliegen hätte, z. B. zusätzliche Kontextinformationen in Form einer aussagekräftigen Dokumentation.
Ein Grund für Archivierung im Sinne des Forschungsdatenmanagements ist die Sicherung der guten wissenschaftlichen Praxis'Die gute wissenschaftliche Praxis (GWP) bildet einen standardisierten Kodex, der als Regelwerk in den Leitlinien der Deutschen Forschungsgemeinschaft (DFG) verankert ist. Die Leitlinien verweisen auf die ethische Verpflichtung jedes/jeder Forschenden, verantwortungsvoll, ehrlich und respektvoll vorzugehen, auch um das allgemeine Vertrauen in Forschung und Wissenschaft zu stärken. Sie können als Orientierung im Rahmen wissenschaftlicher Arbeitsprozesse geltend gemacht werden.' (Data Affairs, Glossar) Weiterlesen. Dazu gehört die Nachvollziehbarkeit, gar die Reproduzierbarkeit der Ergebnisse anhand der Untersuchungsmaterialien und weiterer Forschungsdaten, die während des Forschungsprozesses entstanden sind. Unter Heranziehung der archivierten Daten wird die Möglichkeit geschaffen, die in einer Publikation getätigten Aussagen auf ihre Plausibilität hin zu überprüfen. Unter dem Schlagwort „Replikationskrise” (Pashler et al 2012) hat die Notwendigkeit, das Zustandekommen und die Validität von Forschungsergebnissen genauer zu prüfen, bereits in vielen wissenschaftlichen Disziplinen Einzug gehalten (Open Science Collaboration 2015, Ioannidis 2005, Hoffmann et al 2025). In den Geisteswissenschaften und den historisch arbeitenden Disziplinen ist das Thema bisher nur am Rand aufgetaucht (Schubert 2021). Gerade in der stärker datengetrieben arbeitenden digitalen Geschichtswissenschaft sollte diese Debatte jedoch antizipiert werden, wozu dann auch eine gewissenhafte Archivierung von Forschungsdaten gehört.
Hierbei ist darauf zu achten, die Archivierung von Forschungsdaten von deren Publikation im Sinne einer Datenpublikation zu trennen. In letzterem Fall werden ausgewählte Daten sorgfältig und meist zeitaufwändig aufbereitet und mit dem expliziten Ziel der Nachnutzung durch andere Forschende publiziert. Bei einer reinen Archivierung ist dieser Aufwand geringer. Trotzdem sollten einige aussagekräftigen Daten für die Archivierung aufbereitet werden. So können statistische Daten ohne Dokumentation später im Zweifelsfall nicht mehr verstanden werden, sind so trotz Archivierung wertlos und erfüllen nicht den Zweck der guten wissenschaftlichen Praxis, da eine Reproduktion nicht möglich ist.
Bei Nutzung digitaler Methoden stellt die Archivierung von Software zusätzlich eine besondere Herausforderung dar. Softwarebibliotheken, Entwicklungsumgebungen und Betriebssysteme entwickeln sich extrem schnell weiter und Abwärtskompatibilität spielt dabei oft eine untergeordnete Rolle. Das heißt, dass nicht nur der im Rahmen des Forschungsprojektes erstellte Quellcode benötigt wird, sondern theoretisch auch alle verwendeten Programmbibliotheken. Dies ist oft praktisch kaum umsetzbar und Softwarelizenzen können dies verbieten. Im Kontext der Nationalen Forschungsdateninfrastruktur nimmt sich das Konsortium NFDIxCS (Informatik)3siehe unter: https://nfdixcs.org/ dieser Thematik an und versucht Lösungen zur besseren Archivierbarkeit von Software als Forschungsartefakte zu entwickeln.
Ressourcen
- Forschungsdatenarchiv der eigenen Einrichtung
- Zenodo
Zenodo ist ein frei zugängliches Repositorium der CERN‑Infrastruktur, in dem Forschende Daten, Software und andere wissenschaftliche Materialien langfristig bereitstellen und auch archivieren können. Die Daten können im Bereich Visibility als „restricted“ gekennzeichnet werden: Das bedeutet, dass die hochgeladenen Dateien selbst nur auf Anfrage zugänglich sind. Die Metadaten des Datensatzes bleiben aber öffentlich sichtbar, sodass eindeutig nachvollziehbar ist, dass der Datensatz existiert, wie er beschrieben ist und wie er zitiert werden kann. Damit bietet Zenodo eine verlässliche Möglichkeit, Forschungsdaten zu archivieren, auch wenn der direkte Zugriff eingeschränkt sein muss. Bei sensiblen Daten'Einen eigenen Teilbereich innerhalb der personenbezogenen Daten bilden die sog. besonderen Kategorien personenbezogener Daten. Ihre Definition geht auf den EU-DSGVO Artikel 9 Abs. 1, 2016 zurück, der besagt, dass es sich hierbei um Angaben über Weiterlesen sollte man die dort hochgeladenen Dateien zusätzlich verschlüsseln. Zenodo rät ausdrücklich davon ab, nicht-anonymisierte Personendaten hochzuladen, hierfür soll man sich an spezialisierte Datenzentren wenden.
In benachbarten Disziplinen, insbesondere in den Sozialwissenschaften, existieren bereits spezialisierte Datenzentren, die die langfristige Archivierung von Forschungsdaten anbieten. Diese Einrichtungen sind jedoch in der Regel auf bestimmte Datentypen oder methodische Zugänge ausgerichtet, sodass im Einzelfall geprüft werden muss, welches Datenzentrum für die eigenen Materialien geeignet ist. Für historische Forschungsdaten bedeutet das, frühzeitig zu klären, ob ein Archiv die spezifischen Anforderungen – etwa hinsichtlich Sensibilität, Format oder Kontextualisierung – erfüllen kann. Daher ist es wichtig, bereits in der Planungsphase eines Projekts Kontakt mit potenziellen Datenzentren aufzunehmen und abzustimmen, ob und unter welchen Bedingungen die jeweiligen historischen Daten übernommen werden können.
- re3data
Einen guten Überblick über existierende Repositorien bietet das internationale Verzeichnis re3data. Da die Geschichtswissenschaft mit einer großen Vielfalt an Datentypen arbeitet, lohnt es sich besonders, dort gezielt zu recherchieren, ob es national oder international spezialisierte Repositorien gibt, die zu den eigenen Materialien passen könnten. Die Plattform ermöglicht eine Suche nach Fachgebiet, Datentyp, Zugriffsbedingungen und technischen Kriterien, sodass sich potenziell passende Datenzentren schnell identifizieren lassen.
Endnoten
- 1Datendokumentation dient dazu, zu beschreiben, wie Daten aufgebaut sind, wie sie erhoben wurden und zu welchem Zweck sie ursprünglich verwendet wurden. Bei digitalisierten Schriftquellen wäre beispielsweise zu dokumentieren, mit welchen Methoden diese digitalisiert wurden, an welchem Standort sich die Originale befinden und ob anschließend Methoden wie OCROptical Character Recognition (OCR) bezeichnet die automatische Texterkennung von gedruckten oder maschinengeschriebenen Werken. Der Scan des Durckwerks wird maschinell erfasst und in einen elektronischen Text umgeformt. Die Automatisierung beruht auf dem Erkennen von Mustern und Gesetzmäßigkeiten, dem so genannten maschinellen Lernen. Weiterlesen angewendet wurden und ob es dabei eine Nachkorrektur gab.
- 2Dies ist zumindest die theoretische Überlegung hinter der Forderung nach Nutzung offener Dateiformate. Praktisch sind moderne Dateiformate so komplex, dass selbst ISO-genormte Dateiformate nicht einheitlich zu implementieren sind. Verwiesen sei hier auf die beiden ISO-standardisierten Office-Formate “Open Document Format” von LibreOffice und “Office Open XML” von Microsoft Office. Beide Programme können Dokumente im Format des jeweils anderen öffnen und schreiben, komplexe Formatierungen werden dabei jedoch oft beschädigt.
- 3siehe unter: https://nfdixcs.org/
Literatur und Quellenangaben
Deutsche Forschungsgemeinschaft. 2022. Leitlinien zur Sicherung guter wissenschaftlicher Praxis. Kodex. Zenodo. https://doi.org/10.5281/zenodo.6472827
Forschungsdatendienst OstData. 2019. „Empfohlene Dateiformate für Forschungsdaten zur Langzeitarchivierung”. Zuletzt aufgerufen am 16. Februar 2026. https://www.osmikon.de/fileadmin/uploadMountall/user_upload/2_Dateien_nach_Rubriken_geordnet/4_Forschungsdaten/empfohlene_Dateiformate_fuer_Forschungsdaten_OstData_v1.pdf.
Harold Pashler und Eric-Jan Wagenmakers. 2012. „Editors’ Introduction to the Special Section on Replicability in Psychological Science: A Crisis of Confidence?“. Perspectives on Psychological Science. Band 7, Nr. 6. ISSN 1745-6916, S. 528–530, doi:10.1177/1745691612465253.
Hoffmann, Jerome, Mathias Twardawski, Johanna M. Höhs, Anne Gast, Steffi Pohl und Marie-Ann Sengewald. 2025. „The design of current replication studies: A systematic literature review on the variation of study characteristics“. Advances in Methods and Practices in Psychological Science, 8(2). Advance online publication. doi:10.1177/25152459251328273.
Ioannidis, John P. A. 2005. „Why Most Published Research Findings Are False”. PLoS Medicine 2, no. 8 4. doi:10.1371/journal.pmed.0020124.
Open Science Collaboration. 2015. „Estimating the Reproducibility of Psychological Science”. Science 349, no. 6251. doi:10.1126/science.aac4716
Schmidt, Johannes. 2025. „Der Zettelkasten Niklas Luhmanns“. Niklas Luhmann-Archiv. Universität Bielefeld. Zuletzt aufgerufen am 16. Februar 2026. https://niklas-luhmann-archiv.de/nachlass/zettelkasten
Zitierweise
Lemaire, Marina und Benz, Jacob. 2026. „Archivierung“. HISTOFOX. Das Informations-, Lern- und Lehrportal für Datenkompetenzen in den historisch arbeitenden Disziplinen. NFDI4Memory und Freie Universität Berlin. https://histofox.4memory-dataliteracy.de/artikel/archivierung/