Automatische Texterkennung
Definition
"Textdigitalisierung bezeichnet den Prozess der Umwandlung eines gedruckten oder handschriftlichen Textes in einen maschinell lesbaren elektronischen Text".
(Horstmann 2018)
Dies setzt zunächst die Erstellung von BilddigitalisatenDigitalisate werden hergestellt, indem analoge Materialien wie Bücher, Handschriften, Urkunden, Bilder, Artefakte in digitale Formate überführt werden, die elektronisch gesichert werden. Digitale Daten haben den Vorteil, dass sie vervielfacht, geteilt und maschinell verarbeitet werden können (Data Affairs, Glossar). Weiterlesen voraus. Anschließend erfolgt bei der Automatic Text Recognition (ATR), zu Deutsch Automatische Texterkennung, die Erkennung der Zeichen und Wörter selbst größtenteils automatisiert. Bei gedruckten oder maschinengeschriebenen Werken heißt das Verfahren Optical Character Recognition (OCR)Optical Character Recognition (OCR) bezeichnet die automatische Texterkennung von gedruckten oder maschinengeschriebenen Werken. Der Scan des Durckwerks wird maschinell erfasst und in einen elektronischen Text umgeformt. Die Automatisierung beruht auf dem Erkennen von Mustern und Gesetzmäßigkeiten, dem so genannten maschinellen Lernen. Weiterlesen, bei handschriftlichen Texten Handwritten Text Recognition (HTR)Handwritten Text Recognition (HTR) bezeichnet die automatische Erkennung von Handschriften. Der Scan der Handschrift wird maschinell erfasst und in einen elektronischen Text umgeformt. Die Automatisierung beruht auf dem Erkennen von Mustern und Gesetzmäßigkeiten, dem so genannten maschinellen Lernen (forTEXT). Weiterlesen. Beide Varianten zielen auf die Umwandlung in ein maschinenlesbares Format und werden unter den Oberbegriff ATR (Automatic Text Recognition) zusammengefasst.
Einführung
Bereits BilddigitalisateDigitalisate werden hergestellt, indem analoge Materialien wie Bücher, Handschriften, Urkunden, Bilder, Artefakte in digitale Formate überführt werden, die elektronisch gesichert werden. Digitale Daten haben den Vorteil, dass sie vervielfacht, geteilt und maschinell verarbeitet werden können (Data Affairs, Glossar). Weiterlesen können eine erhebliche Arbeitserleichterung darstellen. Sie können den Gang in ein Archiv oder eine Bibliothek ersetzen und sind bei einer Bereitstellung über das Internet rund um die Uhr zugänglich. Trotzdem sind sie zunächst weiterhin auf den (sehenden) Menschen als Rezipienten ausgerichtet. Automatic Text Recognition (ATR) bietet die Möglichkeit, diese Inhalte auch maschinenlesbar zu machen. Digitalisate sind zunächst nur Bilddateien, in denen Informationen über Farbintensitäten pixelweise abgespeichert sind. Der Computer kann nicht erkennen, ob das sich so ergebende Muster Text, eine Abbildung oder lediglich zusammenhanglose Punkte darstellt. Um daraus maschinell verarbeitbare Informationen zu gewinnen, muss der im Digitalisat abgebildete Text in ein maschinenlesbares Format überführt werden. Dies kann manuell durch Abtippen (keying) erfolgen oder durch automatisierte Methoden. Bei letzteren werden Muster in den Pixeln des Bilddigitalisates erkannt und daraufhin den Pixeln die passenden Buchstaben oder Wörter zugeordnet. Das genaue Verfahren wird detaillierter im Abschnitt Vorgehen erläutert.
Motivation
Die maschinenlesbare Darstellung von Quellen ist der Ausgangspunkt für automatisierte Untersuchungsmethoden der digitalen Analyse. Sie ist ebenfalls Grundlage für eine Annotation von Texten, die diese weiter aufbereitet und durch Auszeichnung von z. B. darin vorkommenden Ereignissen, Orten und Personen neue Zugangsmöglichkeiten durch Vernetzung von Informationen bietet. Zudem ermöglicht ein entsprechend aufbereitetes Digitalisat auch die Durchsuchbarkeit, z. B. nach bestimmten Stichwörtern, und trägt somit zur Arbeitserleichterung bei. Ein händisches Abtippen (keying) ist jedoch nicht nur sehr aufwändig sondern auch fehleranfällig, weswegen in der Regel mehrere Durchgänge notwendig sind. Dies erfordert bei umfangreichen Textsammlungen einen hohen Aufwand und Zeiteinsatz. Das automatische Erfassen von Text (Automatic Text Recognition) ist daher seit der frühen Computernutzung ein Desiderat. Unter günstigen Voraussetzungen können dabei innerhalb von Minuten ganze Werke in ein maschinenlesbares Format überführt werden. Aktuelle Systeme ermöglichen zudem Layouterkennung, wodurch die Zuordnungen von z. B. Tabellen oder Formatierungen wie Überschriften erhalten bleiben. Dies kann von Bedeutung sein, wenn beispielsweise ausgewertet werden soll, wie lang Kapitel in unterschiedlichen Werkgattungen sind oder tabellarische Auflistungen in ihrer ursprünglichen Tabellenform erkennbar bleiben sollen.
Vorgehen
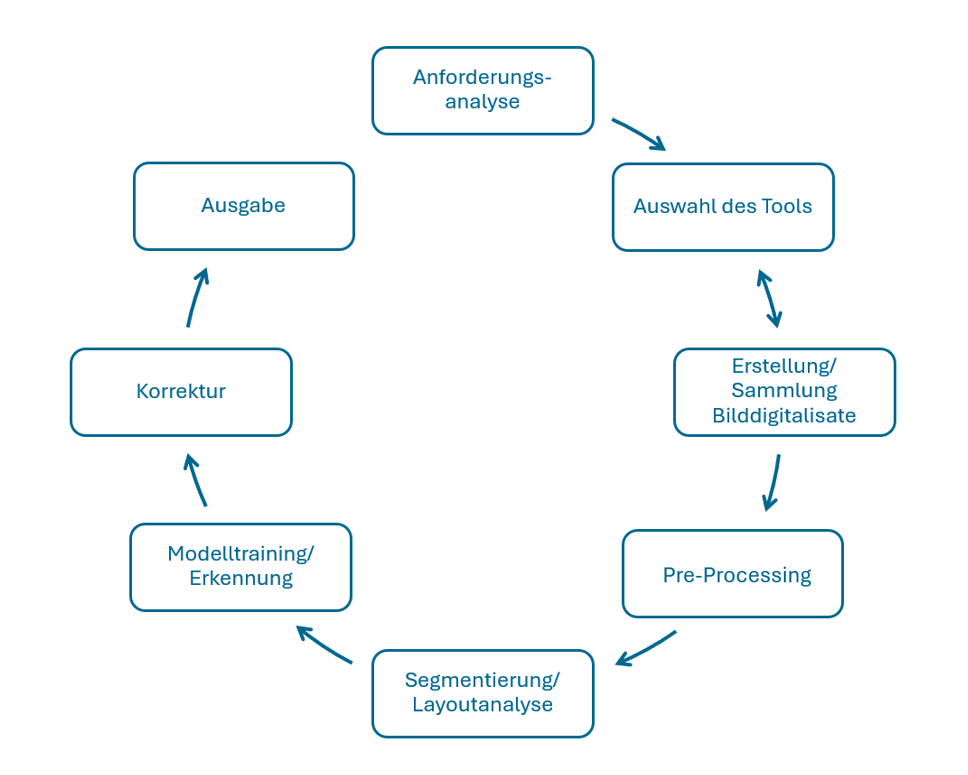
Grafik: Schritte der automatischen Texterkennung (ATR), Anne Voigt, 2026, lizenziert unter CC BY-SA 4.0
- Spezifikation der Anforderungen
Die Ausgangsdaten und das Zielformat entscheiden darüber, welche Funktionen die ATR-Tools haben sollten und somit in die engere Wahl kommen. Daher werden zunächst die Anforderungen in einer Anforderungsanalyse zusammengetragen. Wie ist die Art und Beschaffenheit des Ausgangsmaterials?
- Handelt es sich um handschriftliche Dokumente oder um Druckwerke (Schriftsysteme und verwendete Schriftarten und Formatierungen, vorhandene Annotationen),
- wie ist der Zustand der Daten (z. B. Flecken, Kontrast, Vergilbung …),
- in welchem Format liegen die Daten vor,
- wofür werden die Zieldaten verwendet und
- wie sollen sie ausgegeben werden uvm. (Bach u. a. 2021). - Recherche und Auswahl des Tools (parallel zu Schritt 3)
Für die Recherche und Auswahl passender Tools können noch weitere Aspekte ausschlaggebend sein wie der Funktionsumfang (z. B. verfügbare Modelle und Möglichkeit, eigene Modelle zu trainieren), die Lizenz'In einem Lizenzvertrag oder über eine offene Lizenz legen die Rechteinhabenden fest, wie und unter welchen Bedingungen das eigene urheberrechtlich geschützte Werk durch Dritte verwendet und oder verwertet werden darf. Weiterlesen und damit ggf. anfallende Lizenzkosten, vorhandenes technisches Vorwissen, Aufwand für Installation und Betrieb sowie Handhabbarkeit (Usability), verfügbare Dokumentation oder Supportangebote. Aber auch die Möglichkeit, kollaborativ zu arbeiten, kann die Entscheidung beeinflussen.
Bei einem großen Korpus kann es sich lohnen, die ausgewählten Tools vorab zu testen, um das geeignetste herauszufiltern. Für solche Tests muss nicht zwingend bereits das gesamte Korpus vorliegen. Die Materialien sollten jedoch repräsentativ sein, insbesondere hinsichtlich Seitenaufbau und verwendeter Schriftart, um zuverlässig die Genauigkeit der Ergebnisse der Automatic Text Recognition (ATR) einschätzen zu können. - Sammlung/Erstellung der Bilddigitalisate (parallel zu Schritt 2)
Je nach Ausgangsbedingung müssen die für das Forschungsvorhaben relevanten, bestehenden Bilddigitalisate heruntergeladen oder angefertigt werden. In letzterem Fall ist auf eine entsprechende Qualität zu achten. Die erstellten Scans bzw. Fotografien sollten eine für die Texterkennung hinreichend hohe Auflösung haben. Die Vorlage sollte beim Scannen sorgfältig angeordnet werden, so dass das zu scannende Dokument gerade ausgerichtet und möglichst vollständig ohne Knicke oder Abstände aufliegt, um Verzerrungen beim Ablichten zu vermeiden. Beim Scannen von Büchern kann dies schwierig sein, weshalb viele Buchscanner Algorithmen zur Entzerrung bieten. Hier wäre zu prüfen, ob diese gute Resultate erzielen, so dass verwertbare Bilder entstehen.1Zu technischen Aspekten für gute Digitalisate siehe z. B. Altenhöner u. a. 2023, 15ff.
Wenn die Digitalisate bereits existieren, sollten diese in der höchstmöglichen Auflösungs- und Qualitätsstufe heruntergeladen werden. Faustregel: Je mehr Informationen in einer Bilddatei vorhanden sind, desto besser kann die Software die Inhalte erkennen. Notwendige Reduktionen in der Informationsmenge können immer noch während der weiteren Verarbeitung vorgenommen werden. - Pre-Processing
Ggf. müssen die vorhandenen Digitalisate vor der eigentlichen Texterkennung noch optimiert werden, wenn deren Qualität für den nachfolgenden Prozess nicht ausreicht. Der Schritt dieser Vorverarbeitung umfasst Bildkorrekturen mit einer Bildbearbeitungssoftware wie das Zuschneiden, Drehen, Entzerren und Ausrichten der Vorlagen, um später das bestmögliche Erkennungsergebnis zu erzielen (Souvay und Wil 2024). - Segmentierung/Layoutanalyse
Nach dem Upload der (optimierten) Digitalisate in das Tool analysiert dieses in einem ersten Schritt das Layout des Ausgangsmaterials. Durch die Segmentierung jeder Seite werden die Bereiche ohne Text von Zonen mit Text unterschieden und Textzeilen lokalisiert, um diese später während des Erkennungsvorgangs untersuchen zu können. Je nach Komplexität und Art des Ausgangsmaterials erfolgt dies durch das Tool automatisiert und relativ fehlerfrei oder es wird manuell eingegriffen, indem die Textzonen und -zeilen händisch festgelegt und ggf. auch annotiert werden (Chagué und Scheithauer 2024). - Modelltraining/Erkennung
Nun erfolgt der eigentliche Erkennungsprozess. In diesem Schritt werden aus den Pixeln Buchstaben und Wörter “erkannt” bzw. vielmehr eine wahrscheinliche Buchstabenkombination oder das wahrscheinliche Vorkommen eines Wortes vorhergesagt. Das genaue Vorgehen hängt hierbei von der verwendeten Software und dem darin genutzten Modell ab. Bei Verwendung von ATR-Systemen, die ein Training von Modellen erlauben, wie Transkribus oder eScriptorium, kann es sinnvoll sein, einen Pretest mit möglichst repräsentativem Material durchzuführen, sich die Ergebnisse sowie die Character Error Rate (CER)'Die CER, auf Deutsch 'Zeichenfehlerrate', ist ein Wert zur Bewertung der Genauigkeit der Zeichenerkennung in einer automatischen Transkription auf Zeichenebene. Eine CER von 5 % bedeutet zum Beispiel, dass die automatische Transkription 95 von 100 Zeichen korrekt transkribiert hat' (o. A. 2024). Weiterlesen anzuschauen und Fehler manuell zu korrigieren. Die korrigierten Daten können dann als Trainingsmaterial zur Anpassung des Modells für den restlichen Korpus verwendet werden und so den nachfolgenden Korrekturaufwand minimieren (Pinche und Spychala 2024). - Korrektur
Trotz zuvor trainierter Modelle sind Korrekturen der Ergebnisse notwendig. Diese können halbautomatisch oder manuell erfolgen, wobei letztere die empfohlene Variante ist (Chiffolea und Ondraszek 2024a). - Ausgabe
Je nach Tool und Verwendungszwecken – wie weitere Auszeichnungen und Analysen – wird abschließend das passende Ausgabeformat gewählt. Es gibt reine Textformate, z. B. .txt, oder Exportformate, die alle während der Texterkennung gespeicherten Informationen beinhalten. Diese sogenannten Layout-Formate werden in HTML oder XML kodiert ausgegeben. Die gebräuchlichsten XML-Standards sind PAGE XML'PAGE, auf Deutsch 'Seitenanalyse und Ground Truth Elemente', ist ein XML-Standard für die Kodierung digitalisierter Dokumente. Er ist mit dem ALTO-Format vergleichbar und kann verwendet werden, um die Struktur einer Seite und ihren Inhalt darzustellen.' (o. A. 2024) Weiterlesen und ALTO XML'ALTO, auf Deutsch 'Analysiertes Layout und Textobjekt' ist ein XML-Standard für die Darstellung des physischen Layouts und der logischen Struktur von Text, der mit OCR oder HTR transkribiert wurde. Es behält alle geometrischen Koordinaten des Inhalts (Text, Illustrationen, Grafiken) im Bild bei und ermöglicht die Überlagerung von Bild und Text.' (o. A. 2024) Weiterlesen (Chiffolea und Ondraszek 2024b). Manche Tools erlauben zudem eine Ausgabe als PDF, was vor allem nützlich für eine Durchsuchbarkeit ist, oder es kann ein Export in ein TEITEI (Text Encoding Initiative) bezeichnet sowohl eine Organisationsiehe unter: https://tei-c.org/ als auch ein gleichnamiges Dateiformat. Letzteres basiert auf XML (Extensible Markup Language), einer weit verbreiteten Auszeichnungssprache, und hat sich in den Geisteswissenschaften als Standard zur Kodierung und Auszeichnung von Texten durchgesetzt. Mit Hilfe von TEI ist es möglich, maschinenlesbar Elemente eines Textes auszuzeichnen, wie beispielsweise Absätze oder Überschriften.Die Spezifikation von TEI - auch Guidelines genannt - kann unter https://tei-c.org/release/doc/tei-p5-doc/en/html/index.html eingesehen werden. Zudem können Inhalte wie Personen- oder Ortsnamen als solche markiert und Anmerkungen eines kritischen Apparates eingefügt werden. Im Hinblick auf das Forschungsdatenmanagement ist es vorteilhaft, dass es sich bei TEI um ein Nur-Text-Format handelt, es also auch ohne spezielle Programme von Menschen interpretiert werden kann. Weiterlesen- oder auch Microsoft-Word-Dokument stattfinden.
Anwendungsbeispiele
Beispiele
Beispiel 1: Werkstattbericht zum Workflow mit Transkribus von Julian Helmchen
Julian Helmchen führt in seinem Werkstattbericht „Die Digitalisierung der spätmittelalterlichen Grundbücher Wiens mit Transkribus” unter „3. Der Workflow mit Transkribus” aus, welchen Herausforderungen er bei der Digitalisierung von spätmittelalterlichen Grundbüchern Wiens begegnet ist und wie er beim Trainieren des Modells vorgegangen ist.
https://doi.org/10.58079/143d
Beispiel 2: Einfluss des Ausgangsmaterials auf die Toolwahl beim Bomber's Baedeker
Bach et al. skizzieren in „Bomber’s Baedeker – vom Text zum Bild zur Datenquelle: 3. Datenerhebung – vom Bild zum XML” die Beschaffenheit ihres Ausgangsmaterials, welchen Einfluss dies auf die Wahl des Tools hatte und welche Optimierungen an den ausgegebenen Daten vorgenommen wurden.
Diskussion
In Archiven und Bibliotheken befindet sich eine schier unendliche Menge an analogen Schriftstücken. Durch mehrere Digitalisierungswellen wurden bereits vielfach Bilddigitalisate erstellt, deren Menge ebenfalls weiter zunimmt, jedoch nach wie vor nur einen geringen Umfang des Archivguts abdeckt. Beispielhaft sei genannt, dass im Bundesarchivs 2018 erst ca. ein Prozent des Gesamtbestandes digitalisiert waren (Deutschlandfunk Kultur 2018). Um die bereits vorhandenen Bilddigitalisate bestmöglich nutzen zu können, ist eine Überführung des darauf enthaltenen Texts in ein maschinenlesbares Format unabdingbar. Händisches Abtippen (keying) ist dabei oft aus Ressourcengründen nicht realistisch leistbar. Automatic Text Recognition (ATR) ermöglicht ein schnelles und kostengünstiges Vorgehen und trägt somit dazu bei, Massendigitalisierung erst möglich zu machen.
Problematisch bleibt die stets bestehende Fehlerrate, die allerdings bei händischem Erfassen genauso besteht. Hier ist im Sinne einer methodenkritischen Einordnung zu überlegen, welche Anforderungen an die Erkennung gestellt werden. Soll beispielsweise untersucht werden, ob ein bestimmtes Wort in einem Text vorkommt, kann oft eine höhere Fehlerrate toleriert werden, als wenn gezeigt werden soll, dass ein bestimmtes Wort gar nicht vorkommt (Rehbein 2017, 195).
Handelsübliche – insbesondere kommerzielle – Software erzielt mittlerweile bei gedruckten Texten – auch solchen, die in historischen Schriftarten gesetzt sind – mit einer Fehlerrate von 2-3%, sowohl bezogen auf einzelne Buchstaben als auch auf ganze Wörter sehr gute Ergebnisse (Guan u. a. 2025, 15417). Bei handschriftlichen Aufzeichnungen oder in FrakturFraktur bezeichnet eine typische Schriftgruppe des Mittelalters, bei der die Buchstabenbögen nicht rund sind, sondern aus einzelnen Teilen (Strichen) bestehen. Sie findet heute kaum noch Verwendung, nur im Namen mancher Zeitungen. Weiterlesen gesetzten Texten kann die Fehlerrate jedoch sehr stark ansteigen bis hin zur Unbrauchbarkeit der Ergebnisse. Für diesen Einsatzzweck wurden spezialisierte Tools wie Transkribus und eScriptorium entwickelt, die einen Workflow zum Training spezialisierter Erkennungsmodelle und für die händische Nachkorrektur bieten. Durch Trainieren eines eigenen Modells können die Ergebnisse erheblich verbessert bzw. erst nutzbar werden. Soll ein umfangreiches Konvolut mit derselben Schrift erfasst werden, z. B. sämtliche Briefe einer Person, ist dieses Vorgehen lohnend. Sind hingegen beispielsweise in einem Konvolut sehr viele unterschiedliche Schreiber*innen enthalten, wird das manuelle Training eines Erkennungsmodells nicht zielführend sein, da die Unterschiede in den Handschriften zu groß sind und die Erkennungsrate sich nicht verbessert. Ähnliches gilt für kleine Sammlungen wie z. B. eine Handvoll Urkunden zu einem bestimmten Thema. Für das Training eines Modells muss immer ein gewisser Prozentsatz manuell transkribiert werden, anhand dessen das Programm die Eigenheiten der vorliegenden Schrift erlernen kann. Aufgrund einer benötigten Mindestmenge kann dies bei einem kleinen Korpus bereits die Gesamtzahl an Dokumenten sein, so dass es effizienter ist, diese direkt von Anfang an manuell zu transkribieren. Wie viele Seiten für ein Training als sogenannte Ground Truth'Ground Truth auf Deutsch 'Grundwahrheit” sind Informationen, die als 'wahr” bekannt sind, d.h. als absolut richtig. In unserem Fall handelt es sich um eine manuelle und/oder verifizierte Transkription eines Textes. Ground Truth stellen im ATR-Prozess Trainingsdaten für das Erstellen eines Modells dar.' (Baillot und König, 2024) Weiterlesen benötigt werden, hängt dabei u. a. davon ab, ob ein bestehendes Modell nachtrainiert oder ein vollkommen neues erstellt wird. Als Richtwert können jedoch 20-70 Seiten angesehen werden (Denicolò und Antenhofer 2024, 136). Inwiefern der restliche Workflow von Tools wie Transkribus oder eScriptorium auch bei Verzicht auf ATR hilfreich ist, z. B. das Erkennen von Zeilen oder die gebotene Benutzeroberfläche selbst, hängt vom jeweiligen Projekt und persönlichen Vorlieben ab.
Jüngste KIKünstliche Intelligenz (KI), im Englischen Artificial Intelligence (AI), 'ist ein Teilgebiet der Informatik. Sie imitiert menschliche kognitive Fähigkeiten, indem sie Informationen aus Eingabedaten erkennt und sortiert' (Fraunhofer-Institut für Kognitive Systeme IKS o. D.). Durch technische Fortschritte in der verfügbaren Hardware und der Weiterentwicklung von Algorithmen des maschinellen Lernens haben sich die Fähigkeiten von KI in den letzten Jahren erheblich verbessert. Sie findet produktiven Einsatz beispielsweise im autonomen Fahren, der Steuerung von Fabriken und der Medizin (Fraunhofer-Institut für Kognitive Systeme IKS o. D.). Durch die neu aufgekommenen Large Language Models sind mächtige KI-basierte Werkzeuge zum Umgang mit Text entstanden. Weitere Einsatzgebiete sind auch die Erstellung und die Verarbeitung von Bildmaterial. Weiterlesen-Entwicklungen versprechen, auch ATR-Workflows zu verändern. Vision Language Models (VLM) können Segmentierung und Texterkennung in einem Durchgang durchführen sowie direkt bestimmte Ausgabeformate wie MarkdownMarkdown ist eine Auszeichnungssprache für Text. Es können grundlegende Formatierungen wie Überschriften, Aufzählungen, Tabellen etc. ausgezeichnet werden. Ziel von Markdown ist es, leicht les- und erstellbar zu sein. Softwareentwicklungsplattformen wie GitHub oder GitLab nutzen Markdown beispielsweise für die Formatierung von ReadMe-Dateien und Projekt-Wikis. Ein mit Markdown ausgezeichnetes Beispiel... Weiterlesen oder TEITEI (Text Encoding Initiative) bezeichnet sowohl eine Organisationsiehe unter: https://tei-c.org/ als auch ein gleichnamiges Dateiformat. Letzteres basiert auf XML (Extensible Markup Language), einer weit verbreiteten Auszeichnungssprache, und hat sich in den Geisteswissenschaften als Standard zur Kodierung und Auszeichnung von Texten durchgesetzt. Mit Hilfe von TEI ist es möglich, maschinenlesbar Elemente eines Textes auszuzeichnen, wie beispielsweise Absätze oder Überschriften.Die Spezifikation von TEI - auch Guidelines genannt - kann unter https://tei-c.org/release/doc/tei-p5-doc/en/html/index.html eingesehen werden. Zudem können Inhalte wie Personen- oder Ortsnamen als solche markiert und Anmerkungen eines kritischen Apparates eingefügt werden. Im Hinblick auf das Forschungsdatenmanagement ist es vorteilhaft, dass es sich bei TEI um ein Nur-Text-Format handelt, es also auch ohne spezielle Programme von Menschen interpretiert werden kann. Weiterlesen erstellen, in denen dann auch Layout-Informationen enthalten sind.
Ressourcen
Tools:
- Transkribus
- Webbasierte Software für einen umfassenden Workflow zur Transkription mit besonderem Fokus auf Handschriften; umfangreiche Nutzung von Machine Learning'Machine Learning, bzw. maschinelles Lernen im Deutschen, ist ein Teilbereich der künstlichen Intelligenz. Auf Grundlage möglichst vieler (Text-)Daten erkennt und erlernt ein Computer die häufig sehr komplexen Muster und Gesetzmäßigkeiten bestimmter Phänomene. Daraufhin können die aus den Daten gewonnen Erkenntnisse verallgemeinert werden und für neue Problemlösungen oder für die Analyse von bisher unbekannten Daten verwendet werden.' (Glossar forTEXT) Weiterlesen und KIKünstliche Intelligenz (KI), im Englischen Artificial Intelligence (AI), 'ist ein Teilgebiet der Informatik. Sie imitiert menschliche kognitive Fähigkeiten, indem sie Informationen aus Eingabedaten erkennt und sortiert' (Fraunhofer-Institut für Kognitive Systeme IKS o. D.). Durch technische Fortschritte in der verfügbaren Hardware und der Weiterentwicklung von Algorithmen des maschinellen Lernens haben sich die Fähigkeiten von KI in den letzten Jahren erheblich verbessert. Sie findet produktiven Einsatz beispielsweise im autonomen Fahren, der Steuerung von Fabriken und der Medizin (Fraunhofer-Institut für Kognitive Systeme IKS o. D.). Durch die neu aufgekommenen Large Language Models sind mächtige KI-basierte Werkzeuge zum Umgang mit Text entstanden. Weitere Einsatzgebiete sind auch die Erstellung und die Verarbeitung von Bildmaterial. Weiterlesen-Techniken für Automatic Text Recognition (ATR); ab gewissem Nutzungsumfang kostenpflichtig
- eScriptorium
- Webbasierte Software für einen umfassenden Workflow zur Transkription mit besonderem Fokus auf Handschriften; umfangreiche Nutzung von maschinellem Lernen für ATR, benötigt aber mehr eigenständiges Training der Modelle durch Nutzer*innen als z. B. Transkribus; Open Source, muss aber selbst oder durch Institution gehostet werden
- Abby FineReader
- Kommerzielles, kostenpflichtiges Tool für Optical Character Recognition (OCR), das insbesondere früh mit FrakturschriftFraktur bezeichnet eine typische Schriftgruppe des Mittelalters, bei der die Buchstabenbögen nicht rund sind, sondern aus einzelnen Teilen (Strichen) bestehen. Sie findet heute kaum noch Verwendung, nur im Namen mancher Zeitungen. Weiterlesen umgehen konnte; in vielen Digitalisierungsprojekten genutzt2Zum Tool: https://pdf.abbyy.com/de/
- OCR4all
- Webbasiertes Open Source Tool für OCR-Workflows; insbesondere für Fraktur- und Antiquaschriften des 19. Jahrhunderts geeignet; kann andere OCR-Entwicklungen aus der Wissenschaft wie OCR-D einbinden; muss durch Nutzer*in oder Institution aufgesetzt werden3Zum Tool: https://www.ocr4all.org/
Praxisbeispiel:
- Beispieldatensatz Bomber's Baedeker
- Nutzung einer ATR-Pipeline zur Layouterkennung und Transkription
- Link auf Lehrszenario OCR mit Bomber’s Baedeker
Endnoten
- 1Zu technischen Aspekten für gute Digitalisate siehe z. B. Altenhöner u. a. 2023, 15ff.
- 2Zum Tool: https://pdf.abbyy.com/de/
- 3Zum Tool: https://www.ocr4all.org/
Literatur und Quellenangaben
Altenhöner, Reinhard, Andreas Berger, Christian Bracht, Paul Klimpel, Sebastian Meyer, Andreas Neuburger, Thomas Stäcker, und Regine Stein. 2023. DFG-Praxisregeln „Digitalisierung“. Aktualisierte Fassung 2022. Zenodo. https://doi.org/10.5281/zenodo.7435724
Bach, Felix, Stefan Schmunk, Cristian Secco, und Thorsten Wübbena. 2021. „Bomber’s Baedeker – vom Text zum Bild zur Datenquelle“. In Fabrikation von Erkenntnis – Experimente in den Digital Humanities, herausgegeben von Manuel Burghardt, Lisa Dieckmann, Timo Steyer, Peer Trilcke, Niels Walkowski, Joëlle Weis, und Ulrike Wuttke. Wolfenbüttel. https://doi.org/10.17175/sb005_004
Baillot, Anne und Mareike König (Hg.). 2024. „Glossar ATR Deutsch“. Automatic Text Recognition. Harmonising ATR Workflows. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/glossar-atr-deutsch
Chagué, Alix und Hugo Scheithauer. 2024. „ATR Schritt 4 – Layoutanalyse”. Automatic Text Recognition. Harmonising ATR Workflow, herausgegeben von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/category/layout-analysis
Chiffoleau, Floriane und Sarah Ondrasze. 2024a. „ATR Schritt 5 – Texterkennung und Post-ATR-Korrektur”. Automatic Text Recognition. Harmonising ATR Workflows, herausgegeben. von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/2145.
Chiffoleau, Floriane und Sarah Ondrasze. 2024b. „ATR Schritt 6 – Endformate und Wiederverwendung”. Automatic Text Recognition. Harmonising ATR Workflows, herausgegeben von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/439
Denicolò, Barbara, und Christina Antenhofer. 2024. „Von der Datenerfassung zur Annotation (Transkribus). Quellen erfassen, analysieren, transkribieren und annotieren“. In Digital Humanities in den Geschichtswissenschaften, herausgegeben von Christina Antenhofer, Christoph Kühberger, und Arno Strohmeyer, 125–142. utb 6116. Wien: Böhlau Verlag.
Deutschlandfunk Kultur. 2018. „Sicherung der Archive – Lediglich ein Prozent des Bundesarchivs digitalisiert“. Zuletzt aufgerufen am 28. Januar 2026. https://www.deutschlandfunkkultur.de/sicherung-der-archive-lediglich-ein-prozent-des-100.html.
Guan, Shuhao, Moule Lin, Cheng Xu, Xinyi Liu, Jinman Zhao, Jiexin Fan, Qi Xu, und Derek Greene. 2025. „PreP-OCR: A Complete Pipeline for Document Image Restoration and Enhanced OCR Accuracy“. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), herausgegeben von Wanxiang Che, Joyce Nabende, Ekaterina Shutova, und Mohammad T. Pilehvar, 15413–25. Wien: Association for Computational Linguistics. https://doi.org/10.18653/v1/2025.acl-long.749.
Helmchen, Julian. 2025. „Die Digitalisierung der spätmittelalterlichen Grundbücher Wiens mit Transkribus”. Mittelalter. Zuletzt aufgerufen am 4. Februar 2026. https://doi.org/10.58079/143do
Horstmann, Jan. 2018. „Möglichkeiten der Textdigitalisierung“. forTEXT. Literatur digital erforschen. Zuletzt aufgerufen am 28. Januar 2026. https://fortext.net/routinen/methoden/moeglichkeiten-der-textdigitalisierung.
Rehbein, Malte. 2017. „Digitalisierung“. In Digital Humanities. Eine Einführung, herausgegeben von Fotis Jannidis, Hubertus Kohle, und Malte Rehbein, 179–198. Stuttgart: J. B. Metzler.
Souvay, Hippolyte und Larissa Wil. 2024. „ATR Schritt 3 – Pre-Processing und Bildoptimierung”. Automatic Text Recognition. Harmonising ATR Workflows, herausgegeben von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/3742
Zitierweise
Benz, Jacob und Voigt, Anne. 2026. „Automatische Texterkennung“. HISTOFOX. Das Informations-, Lern- und Lehrportal für Datenkompetenzen in den historisch arbeitenden Disziplinen. NFDI4Memory und Freie Universität Berlin. https://histofox.4memory-dataliteracy.de/artikel/automatische-texterkennung/