Bei einem Algorithmus handelt es sich um ein schrittweises Verfahren zur Transformation bzw. Verarbeitung von Daten. Oft wird das Verfahren mehrfach hintereinander angewandt, bis die Verarbeitung abgeschlossen ist. Ein Algorithmus ist die Beschreibung dieses Verfahrens, unabhängig davon, ob die Schritte anschließend von einem Computer oder einem Menschen durchgeführt werden. Der Begriff ist aus dem Griechischen sowie Lateinischen entlehnt und geht auf eine Entstellung des Namens des persisch-arabischen Mathematikers Al-Ḫwārizmī zurück (DWDS). |
|---|
Bei analogen Forschungsmaterialien im geschichtswissenschaftlichen Kontext handelt es sich z. B. um Bücher, Handschriften, Urkunden, Bilder, Fotos und andere Artefakte, die für eine Forschungsfrage recherchiert oder gesammelt werden. Um sie digital nachnutzbar und maschinenlesbar zu machen, müssen sie zunächst digitalisiert und mit entsprechenden Metadaten versehen oder annotiert werden, um sie weiterverarbeitbar und analysieren zu können. Die Organisation OpenAIRE liefert zum sicheren Umgang mit analogen, nicht-digitalen Forschungsdaten eine Handreichung1siehe: https://www.openaire.eu/non-digital-data-guide. | |
|---|---|
| Verwandte Glossareinträge | |
„Laut Bundesdatenschutzgesetz (BDSG § 3, Abs. 6 in der bis 24.05.2018 gültigen Fassung) versteht man unter Anonymisierung alle Maßnahmen der Veränderung personenbezogener Daten derart, „dass die Einzelangaben über persönliche oder sachliche Verhältnisse nicht mehr oder nur mit einem unverhältnismäßig großen Aufwand an Zeit, Kosten und Arbeitskraft einer bestimmten oder bestimmbaren natürlichen Person zugeordnet werden können.“ Anonymisierte Daten sind demnach Daten, die keinen Rückschluss (mehr) auf die betroffene Person geben. Sie unterliegen damit nicht dem Datenschutz bzw. der Datenschutz-Grundverordnung (DSGVO)“. (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Archivierung meint das Aufbewahren und Zugänglichmachen von Forschungsdaten und -materialien. Das Ziel der Archivierung ist es, den Zugang zu Forschungsdaten über einen längeren Zeitraum hinweg zu ermöglichen. So können zum einen archivierte Forschungsdaten durch Dritte für eigene Forschungsfragen als Sekundärdaten nachgenutzt werden. Zum anderen bleiben Forschungsverläufe so nachprüfbar und nachvollziehbar. Daneben gibt es auch die Langzeitarchivierung (LZA), welche die langfristige Nutzbarkeit über einen nicht definierten Zeitraum hinweg sicherstellen soll. Die LZA zielt auf Erhalt der Authentizität, Integrität, Zugänglichkeit und Verständlichkeit von Daten ab. In vielen Fachdisziplinen hat sich eine mindestens zehnjährige Aufbewahrungsfrist von Forschungsdaten als Standard etabliert. Weil dieser Zeitraum von technischen Veränderungen betroffen sein kann, bedarf es einer regelmäßigen Überprüfung der Daten im Hinblick auf ihre Erhaltung und Nutzbarkeit. | |
|---|---|
| Verwandte Glossareinträge | |
Mit der automatischen Texterkennung werden in Digitalisaten enthaltene gedruckte oder handschriftliche Texte in maschinenlesbare, durchsuchbare Texte umgewandelt. | |
|---|---|
| Verwandte Glossareinträge | |
„Der Begriff Backup bedeutet Datensicherung beziehungsweise Datenrettung und bezeichnet das Kopieren von Daten als Vorsorge für den Fall, dass es durch einen Schaden z. B. an der Festplatte oder durch versehentliches Löschen zu Datenverlusten kommt. Mit einem Backup können die Daten wiederhergestellt werden. Dafür wird der Datensatz auf einem anderen Datenträger zusätzlich gesichert (Sicherungskopie) und offline oder online abgelegt.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Einen eigenen Teilbereich innerhalb der personenbezogenen Daten bilden die sog. besonderen Kategorien personenbezogener Daten. Ihre Definition geht auf den EU-DSGVO Artikel 9 Abs. 1, 2016 zurück, der besagt, dass es sich hierbei um Angaben über
der Betroffenen handelt. Hierunter fallen auch genetische und biometrische Daten (z. B. Fingerabdruck) zur Identifizierung einer natürlichen Person. Laut Datenschutz-Grundverordnung gelten diese Angaben als „sensibel“, weil ihre Erhebung, Verarbeitung oder Nutzung erhebliche Risiken für die Betroffenen mit sich bringen kann. Sie unterliegen daher besonderen Pflichten und Verarbeitungsbedingungen. Grundsätzlich gilt, dass zur Verarbeitung personenbezogener Daten das Einverständnis der betroffenen Personen einzuholen ist. Ausnahmen gelten, wenn die Daten von der betroffenen Person selbst öffentlich gemacht wurden oder ein erhebliches öffentliches Interesse besteht (EU-DSGVO 2016, Artikel 9 Abs. 2). Gerade in ethnografischen Forschungsvorhaben entstehen regelmäßig personenbezogene Daten, die laut Datenschutz-Grundverordnung in hohem Maße als sensibel gelten.“ (Data Affairs, Glossar) | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
„Die CARE-Prinzipien wurden 2019 von der Global Indigenous Data Alliance (GIDA) etabliert. Sie fungieren als Komplement zu den FAIR-Prinzipien und gelten als Hilfswerkzeug, um Forschungskontexte und ihre historische Einbettung sowie Machtasymmetrien im Feld stärker zu fokussieren. Das Akronym steht für Collective Benefit (Gemeinwohl), Authority to Control (Kontrolle der Forschungsteilnehmenden über die eigene Repräsentation), Responsibility (Verantwortung seitens Forschender) und Ethics (Berücksichtigung ethischer Aspekte). Durch die CARE-Prinzipien soll der gerechte, respektvolle und ethische Umgang mit Forschungsteilnehmenden und den aus der Forschung generierten Daten hinsichtlich des Data Sharing betont und berücksichtigt werden. Die CARE-Prinzipien sind somit in allen Phasen des Forschungsdatenlebenzyklus und des Forschungsdatenmanagements relevant.“ (Data Affairs, Glossar) | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
„Die CER, auf Deutsch „Zeichenfehlerrate“, ist ein Wert zur Bewertung der Genauigkeit der Zeichenerkennung in einer automatischen Transkription auf Zeichenebene. Eine CER von 5 % bedeutet zum Beispiel, dass die automatische Transkription 95 von 100 Zeichen korrekt transkribiert hat“ (o. A. 2024). | |
|---|---|
| Verwandte Glossareinträge | |
„Close Reading bezeichnet die sorgfältige Lektüre und Interpretation eines einzelnen oder weniger Texte“2 (vgl. auch Distant Reading als Gegenbegriff) (forTEXT o.D.). | |
|---|---|
| Verwandte Glossareinträge | |
„Creative-Commons-Lizenzen sind von der Non-Profit-Organisation Creative Commons vorgefertigte Lizenzverträge, mit denen die Urheberrechtsinhabenden der Öffentlichkeit die Nutzungsrechte am eigenen kreativen Werk einräumen können. Sobald ein unter CC-Lizenz stehendes Werk im Sinne des Lizenzvertrages von Dritten genutzt wird, kommt der Vertrag zustande (TUM 2023, 5). Die bestehenden Lizenzen sind aufgrund des standardisierten Baukastenprinzips auch ohne juristisches Wissen leicht nachvollziehbar, mit über 2 Milliarden CC-lizenzierten Werken weit verbreitet und unterstützen die Kultur des Teilens und Wiederverwendens. Sie sind sowohl menschen- als auch maschinenlesbar (Creative Commons 2023a; 2023b). Die einzelnen Bausteine legen jeweils eine Bedingung für die Wiederverwendung fest, werden mit Symbolen visualisiert und haben einen hohen Wiedererkennungswert, sodass Nachnutzende schnell verstehen, was sie bei einer Wiederverwendung beachten müssen. Aus den Bausteinen setzen sich dann die weltweit rechtsgültigen Lizenzverträge zusammen. BAUSTEINE BY Attribution – Der Name des*der Urheber*in muss genannt werden. NC Non-Commercial – Das Werk darf nicht kommerziell verwertet werden. ND No Derivates – Das Werk darf nicht verändert werden. SA Share Alike – Weitergabe des Werkes muss unter gleichen Bedingungen (Lizenz) erfolgen. Aus diesen setzen sich die sechs Lizenzen zusammen (Creative Commons, 2023b).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Data Journals bieten analog zu klassischen wissenschaftlichen Zeitschriften die Möglichkeit, Forschungsdaten mit Peer-Review-Prozess zu publizieren. Data Journals werden von Verlagen herausgebracht und sind in der Regel mit Kosten für die Lesenden oder Autor*innen verbunden.“ (Data Affairs, Glossar) |
|---|
„Data Sharing meint das Teilen bzw. Weitergeben von Daten. Dabei gilt es gemäß den entsprechenden Anforderungen der Forschung, die Daten so offen wie möglich und so geschlossen wie nötig (Europäische Kommission 2021) darzulegen und zur Verfügung zu stellen. Insbesondere im Hinblick auf die Nachnutzung und den Umgang mit sensiblen, personenbezogenen Daten muss gründlich überprüft werden, ob und in welcher Form das Archivieren und Teilen von Daten mit anderen Wissenschaftler*innen und der Öffentlichkeit möglich und sinnvoll ist. Der Imperativ des Data Sharing bildet im Rahmen der Open-Science-Bewegung einen breiten Konsens in der Wissenschaft, ist aber aus sozial- und kulturanthropologischer Sichtweise kritisch zu betrachten und abzuwägen.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Der Dateiname identifiziert in Verbindung mit dem zur Datei führenden Verzeichnispfad eine Datei eindeutig. Er besteht aus der eigentlichen Benennung und der Erweiterung oder Endung. Die Erweiterung gibt Hinweise auf die Dateiart (Text, Bild, Video) und den Typ (.docx für Textdatei, .mp4 für Videodateien oder .png für Bilddateien) und bestimmt auch, in welchem Programm die Datei standardmäßig geöffnet wird.“ (Data Affairs, Glossar) | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
„Die Dateiendung gibt an, um welche Art von Datei es sich handelt (Dokument, Bild, Video, etc.) und in welchem Format sie gespeichert ist. Die Dateiendung bestimmt auch, mit welchem Programm die Datei standardmäßig geöffnet wird. Sie sollte unbedingt dem tatsächlichen Dateityp entsprechen und nicht geändert werden.“ (Data Affairs, Glossar)
| |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Synonyme Glossareinträge | |||||||||||||||||||||||
| Verwandte Glossareinträge | |||||||||||||||||||||||
Die Dateiendung gibt an, um welche Art von Datei es sich handelt (Dokument, Bild, Video, etc.) und in welchem Format sie gespeichert ist. Die Dateiendung bestimmt auch, mit welchem Programm die Datei standardmäßig geöffnet wird. Sie sollte unbedingt dem tatsächlichen Dateityp entsprechen und nicht geändert werden.“ (Data Affairs, Glossar)
| |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Synonyme Glossareinträge | |||||||||||||||||||||||
| Verwandte Glossareinträge | |||||||||||||||||||||||
Die Begriffe Dateityp und Dateiformat werden meist synonym verwendet, bezeichnen jedoch verschiedene Dinge. | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
„Der Dateiname identifiziert in Verbindung mit dem zur Datei führenden Verzeichnispfad eine Datei eindeutig. Er besteht aus der eigentlichen Benennung und der Erweiterung oder Endung.“ (Data Affairs, Glossar) | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
Die Begriffe Dateityp und Dateiformat werden meist synonym verwendet, bezeichnen jedoch verschiedene Dinge. „Der Dateityp ist eine Kategorisierung von Dateien nach Art des Inhalts der Daten, zum Beispiel Bild, Text, Video, Audio, ohne sich auf die spezifische technische Implementierung zu beziehen.“ (Lernzielmatrix Glossar 2025) | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
„Forschungsdaten bilden nicht nur die Basis wissenschaftlicher Veröffentlichungen der jeweiligen Forscher*innen, sondern werden in vielen Fällen anderen zugänglich gemacht. Dies setzt voraus, dass Forschungsdaten verständlich dokumentiert sind. Unverzichtbar wird dies, wenn eine Datenpublikation beabsichtigt ist. Eine zentrale Rolle für das Finden, Durchsuchen und Nutzen von Forschungsdaten spielen Metadaten, also Daten, die strukturierte Informationen über andere Daten enthalten. In verschiedenen Wissenschaftskreisen haben sich für die Dokumentation in Form von Metadaten sogenannte Metadatenstandards etabliert, die Konventionen für die Beschreibung und Dokumentation von Forschungsdaten über Metadaten festlegen. Eine angemessene Dokumentation gehört zu jeder guten wissenschaftlichen Praxis.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Ein Datenmanagementplan (DMP) beschreibt und dokumentiert den Umgang mit den Forschungsdaten und Forschungsmaterialien einer Forschung während und nach der Projektlaufzeit. Im DMP wird festgehalten, wie die Daten und Materialien entstehen, aufbereitet, gespeichert, organisiert, veröffentlicht, archiviert und ggf. geteilt werden. Zudem werden im DMP Verantwortlichkeiten und Rechte geregelt. Als „living document“ (also ein dynamisches Dokument, das sich fortlaufend in Bearbeitung und Veränderung befindet) wird der DMP im Laufe des Projektes regelmäßig geprüft und bei Bedarf angepasst.“ (Data Affairs, Glossar) |
|---|
„Im Zuge des digitalen Wandels wächst die Vielfalt an Methoden und Verfahren zur Erzeugung, Verarbeitung und Verbreitung von Daten rasant. Je mehr Entscheidungen auf Grundlage von digitalen Daten getroffen werden, desto wichtiger werden Fragen nach deren Herkunft und Qualität. Die Qualitätssicherung von Forschungen gehört zu jeder guten wissenschaftlichen Praxis und sichert wiederum die Wissenschaftlichkeit. Der Rat für Informationsinfrastrukturen (RfII) empfiehlt dabei in einem im Jahr 2019 veröffentlichten Positionspapier, die Dokumentation von Forschungsdaten als methodische Kernaufgabe in der Forschungspraxis zu verankern. Hochschulen und Wissenschaftsorganisationen fordert der RfII auf, die Sicherung und Steigerung der Datenqualität in ihre jeweiligen Forschungsstrategien zu integrieren. Auch die Forschungsförderung kann hier Anreize setzen und zeitliche Freiräume gewähren (Rfll 2019, 172).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Datenschutz beinhaltet Maßnahmen gegen ein unrechtmäßiges Erheben, Speichern, Teilen und Nachnutzen von personenbezogenen Daten. Der Datenschutz stützt sich auf das Recht der Selbstbestimmung von Individuen in Bezug auf den Umgang mit ihren Daten und ist in der Datenschutz-Grundverordnung (EU-DSGVO), dem Bundesdatenschutzgesetz und in den entsprechenden Gesetzen der Bundesländer verankert. Ein Verstoß gegen datenschutzrechtliche Vorschriften kann strafrechtliche Konsequenzen nach sich ziehen.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Unter Datensicherheit werden alle präventiven Maßnahmen physischer und technischer Art verstanden, die dem Schutz digitaler und auch analoger Daten dienen. Datensicherheit soll für deren Verfügbarkeit bürgen, sowie die Vertraulichkeit und Integrität der Daten gewährleisten. Beispiele für Maßnahmen sind: Passwortschutz für Geräte und Online-Plattformen, Verschlüsselungen für Software z. B. E-Mails und auch Hardware, Firewalls, regelmäßige Softwareupdates sowie sicheres Löschen von Dateien.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Datensicherung beschreibt den Prozess des sicheren Aufbewahrens von Informationen (Daten) auf einem Medium bzw. generell innerhalb eines Systems, sodass sie später ohne Verlust wieder abgerufen, verarbeitet oder verwaltet werden können. Dabei umfasst die Datensicherung sowohl den physischen als auch den digitalen Bereich. | |
|---|---|
| Verwandte Glossareinträge | |
„Datenspeicherung bezeichnet allgemein den Vorgang des Speicherns von Daten auf einem Trägermaterial oder Datenträger (digitalisierte Daten). | |
|---|---|
| Verwandte Glossareinträge | |
Ein Debugger ist ein Programm zur Untersuchung von Fehlern in Software. Es wird genutzt, um während der Ausführung eines Programmes Einfluss auf dieses nehmen zu können und den internen Zustand zu betrachten. Mit Hilfe eines Debuggers können u. a. beispielsweise die Werte von Variablen eingesehen und es kann die Ausführung an bestimmten Stellen unterbrochen werden. | |
|---|---|
| Verwandte Glossareinträge | |
„Digitale Methoden nutzen computationelle Verfahren zur Gewinnung und Aufbereitung von Daten sowie zur Analyse dieser Daten. Digitale Methoden bilden einen neuen, interdisziplinären Forschungsbereich, bei dem es im Kern darum geht, computerbasierte Verfahren zu entwickeln und zu verwenden, die es ermöglichen gesellschaftliche, soziale und kulturelle Phänomene zu analysieren. Die wichtigsten beiden Richtungen sind die Digital Humanities (DH) und die Computational Social Sciences (CSS). Eine gute Einführung in die digitalen Methoden in der qualitativen Forschung bietet Franken (2023).“ (Data Affairs, Glossar) |
|---|
Digitalisate werden hergestellt, indem analoge Materialien wie Bücher, Handschriften, Urkunden, Bilder, Artefakte in digitale Formate überführt werden, die elektronisch gesichert werden. Digitale Daten haben den Vorteil, dass sie vervielfacht, geteilt und maschinell verarbeitet werden können (Data Affairs, Glossar). | |
|---|---|
| Verwandte Glossareinträge | |
Bei der Digitalisierung werden analoge Materialien in digitale Formate, sogenannte Digitalisate, überführt. Diese Formate können weitergegeben, gespeichert, archiviert und maschinell verarbeitet werden. | |
|---|---|
| Verwandte Glossareinträge | |
„Distant Reading ist ein Ansatz aus den digitalen Literaturwissenschaften, bei dem computationelle Verfahren auf häufig große Mengen an Textdaten angewandt werden, ohne dass die Texte selber gelesen werden“. (forTEXT 2025) | |
|---|---|
| Verwandte Glossareinträge | |
„Die Abkürzung DOI steht für Digital Object Identifier und ist ein eindeutiger und dauerhafter (persistenter) Identifikator für digitale Objekte, z. B. für Artikel und Beiträge in wissenschaftlichen Veröffentlichungen aber auch Veröffentlichungen von Vorträgen und Lehrmaterialien. Ein DOI muss initial in der zentralen Datenbank, der International DOI Foundation, registriert werden3 siehe: https://www.doi.org/. Ein Persistent Identifier verweist auf das Objekt selbst und nicht auf seinen Standort im Internet (wie die URL-Adressen). Ändert sich der Standort eines mit einem Persistent Identifier assoziierten digitalen Objekts, so bleibt der Identifikator derselbe. Es muss lediglich in der Identifikator-Datenbank der URL-Standort geändert oder ergänzt werden. So wird sichergestellt, dass ein Datensatz dauerhaft auffindbar, abrufbar und zitierbar bleibt (Forschungdaten.info 2023). Ein DOI besteht immer aus einem Präfix und einem Suffix, die durch einen Schrägstrich getrennt sind, z. B. doi: 10.17169/refubium-35157.2. Dabei referenziert das Suffix refubium-35157.2 die Veröffentlichung „Zur Teilbarkeit ethnografischer Forschungsdaten. Oder: Wie viel Privatheit braucht ethnografische Forschung?“, die im Refubium der Freien Universität Berlin 17169 archiviert ist (siehe: https://refubium.fu-berlin.de/handle/fub188/35442.2). 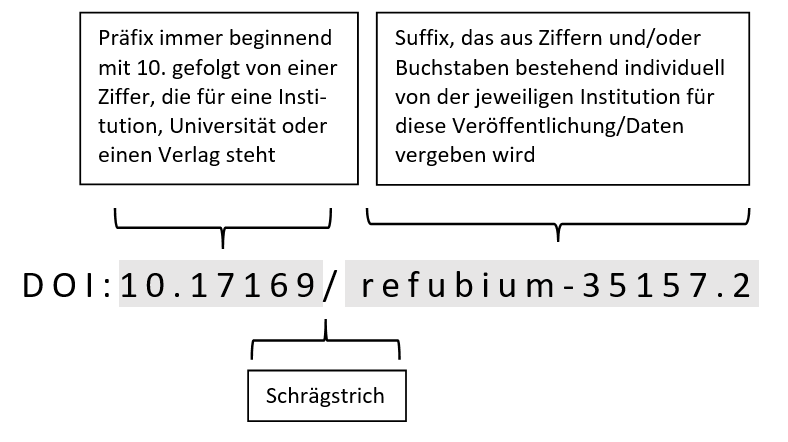 Grafik: Bestandteile des DOI, Anne Voigt, lizenziert unter CC BY-SA 4.0 DOIs können in verschiedenen Formaten – je nach Zitierstil – dargestellt werden.
| |
|---|---|
| Verwandte Glossareinträge | |
Der Begriff Entität bezeichnet je nach Fachrichtung unterschiedliche Konzepte. Im Bereich der Normdaten sind damit konkrete Dinge wie z. B. Personen, Sachen, Werke, aber auch abstrakte Konzepte gemeint, die entsprechend beschrieben werden können. Entitäten werden in Normdaten mit dazugehöriger Beschreibung und weiteren Informationen verwaltet. In Dokumenten können diese Entitäten anschließend identifiziert und mit dem Eintrag in der Normdatei verknüpft werden. | |
|---|---|
| Verwandte Glossareinträge | |
„Die FAIR-Prinzipien wurden 2016 erstmals von der FORCE 11-Community (The Future of Research Communication and e-Scholarship) entwickelt. FORCE11 ist eine Gemeinschaft von Wissenschaftlern, Bibliothekaren, Archivaren, Verlegern und Forschungsförderern, die durch den effektiven Einsatz von Informationstechnologie einen Wandel in der modernen wissenschaftlichen Kommunikation herbeiführen und so eine verbesserte Wissenserstellung und -weitergabe unterstützen will. Das primäre Ziel liegt in der transparenten und offenen Darlegung wissenschaftlicher Erkenntnisprozesse. Demnach sollten Daten online findable (auffindbar), accessible (zugänglich), interoperable (kompatibel) und reusable (wiederverwendbar) abgelegt und strukturiert sein. Ziel ist es, Daten langfristig aufzubewahren und im Sinne der Open Science und des Data Sharing für eine Nachnutzung durch Dritte bereitzustellen. Genaue Definitionen der FORCE11 selbst können auf der Website nachgelesen werden4 siehe: https://force11.org/info/the-fair-data-principles/. Die FAIR-Prinzipien berücksichtigen ethische Aspekte der Weitergabe von Daten in sozialwissenschaftlichen Kontexten nicht hinreichend, weshalb sie um die CARE-Prinzipien ergänzt wurden.“ (Data Affairs, Glossar) | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
„Forschungsdaten sind (digitale) Daten, die während wissenschaftlicher Tätigkeit (z. B. durch Messungen, Befragungen, Beobachtungen, Experimente, Quellenarbeit) entstehen. Sie bilden eine Grundlage wissenschaftlicher Arbeit und dokumentieren deren Ergebnisse. Daraus ergibt sich ein disziplin- und projektspezifisches Verständnis von Forschungsdaten mit unterschiedlichen Anforderungen an die Aufbereitung, Verarbeitung und Verwaltung der Daten: dem sogenannten Forschungsdatenmanagement (FDM).“ (Forschungsdaten.info 2026) | |
|---|---|
| Verwandte Glossareinträge | |
„Das Modell des Forschungsdatenlebenszyklus stellt sämtliche Phasen dar, die Forschungsdaten vom Zeitpunkt der Erhebung bis zu ihrer Nachnutzung durchlaufen können. Die Phasen sind an bestimmte Aufgaben gekoppelt und können variieren (Forschungsdaten.info 2026). Allgemein umfasst der Forschungsdatenlebenszyklus folgende Teilbereiche:
| |
|---|---|
| Verwandte Glossareinträge | |
„Beim Forschungsdatenmanagement geht es um einen verantwortungsvollen und reflektierten Umgang mit Forschungsdaten. Anhand spezifischer Maßnahmen und Strategien sollen Forschungsdaten sorgfältig organisiert, gepflegt und aufgearbeitet werden. Ziel ist es, sie im Sinne einer guten wissenschaftlichen Praxis langfristig zu speichern und für Dritte zugänglich und nachnutzbar zu machen. Somit soll eine Überprüfung wissenschaftlicher Aussagen vereinfacht, Nachweise gesichert und weitere Auswertungen und Analysen an den Daten vollzogen werden können.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Das Forschungsdatenzentrum Qualiservice stellt qualitative sozialwissenschaftliche Daten für die wissenschaftliche Nachnutzung zur Verfügung. Vom Rat für Sozial- und Wirtschaftswissenschaften (RatSWD) 2019 akkreditiert, basiert es auf dessen Qualitätssicherungskriterien. Neben der (Nach-)Nutzung von Daten gibt es für Forschende die Möglichkeit, ihre Forschungsdaten zu teilen und zu organisieren. Dabei steht das Team von Qualiservice beratend zur Seite. Qualiservice bekennt sich zu den DFG-Richtlinien zur Sicherung guter wissenschaftlicher Praxis und berücksichtigt darüber hinaus die FAIR Guiding Principles for Scientific Data Management and Stewardship sowie die OECD Principles and Guidelines for Access to Research Data from Public Funding5Mehr Informationen unter: https://www.qualiservice.org/de/.“ (Data Affairs, Glossar) |
|---|
Fraktur bezeichnet eine typische Schriftgruppe des Mittelalters, bei der die Buchstabenbögen nicht rund sind, sondern aus einzelnen Teilen (Strichen) bestehen. Sie findet heute kaum noch Verwendung, nur im Namen mancher Zeitungen.  |
|---|
„Förderinstitutionen sind all jene Einrichtungen, die wissenschaftliche Forschung finanziell fördern, also Stiftungen, Vereine oder andere Organisationen. Die meisten dieser Einrichtungen im internationalen Raum haben dabei Richtlinien für das Forschungsdatenmanagement (FDM) von Forschungsprojekten eingeführt, d. h. eine mögliche finanzielle Förderung ist an Bedingungen und Forderungen zum Umgang mit Forschungsdaten geknüpft. Zu den bekanntesten Förderinstitutionen im deutschsprachigen Raum gehören das Bundesministerium für Bildung und Forschung (BMBF) selbst, die Bildungs- und Wissenschaftsministerien der Bundesländer, die Deutsche Forschungsgemeinschaft (DFG), die Volkswagenstiftung oder der Österreichische Wissenschaftsfonds (FWF) sowie der Schweizer Nationalfonds (SNF).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Die Gemeinsame Normdatei (GND) ist eine deutschsprachige Normdatei, die von der Deutschen Nationalbibliothek zusammen mit Partnern aus den deutschsprachigen Bibliotheksverbünden und weiteren Einrichtungen gepflegt wird. Sie umfasst Einträge zu einer breiten Auswahl an Entitäten aus den Bereichen Personen, Körperschaften, Konferenzen, Geografika, Sachbegriffen und Werken (Gemeinsame Normdatei (GND) 2025). | |
|---|---|
| Verwandte Glossareinträge | |
Ein Geoinformationssystem (GIS) ist eine Software zur Verarbeitung, Speicherung, Analyse und Präsentation von Geodaten. Bei diesen handelt es sich um Daten mit räumlichem Bezug, also Koordinatenangaben zu einem bestimmten Ort. Sie umfassen einerseits diese Koordinaten und andererseits Sachinformationen, beispielsweise was sich zu welcher Zeit an diesem Ort befand oder noch befindet (Geodaten und Geoinformationssystem). Im Rahmen historischer Forschung werden GIS-Anwendungen vor allem zur Analyse und Darstellung von räumlichen Aspekten genutzt, beispielsweise um Reisewege von Herrschern zu visualisieren oder frühere Stadtbilder zu rekonstruieren. |
|---|
„Die Global Indigenous Data Alliance (GIDA) ist ein Netzwerk von Forschenden, Datenpraktiker*innen und politischen Aktivist*innen, die sich dafür einsetzen, dass indigene Gruppen
Die GIDA Global Indigenous Data Alliance (GIDA) hat 2019 die CARE-Prinzipien etabliert. | |
|---|---|
| Verwandte Glossareinträge | |
„Ground Truth auf Deutsch „Grundwahrheit” sind Informationen, die als „wahr” bekannt sind, d.h. als absolut richtig. In unserem Fall handelt es sich um eine manuelle und/oder verifizierte Transkription eines Textes. Ground Truth stellen im ATR-Prozess Trainingsdaten für das Erstellen eines Modells dar.“ (Baillot und König, 2024) | |
|---|---|
| Verwandte Glossareinträge | |
„Die gute wissenschaftliche Praxis (GWP) bildet einen standardisierten Kodex, der als Regelwerk in den Leitlinien der Deutschen Forschungsgemeinschaft (DFG) verankert ist. Die Leitlinien verweisen auf die ethische Verpflichtung jedes/jeder Forschenden, verantwortungsvoll, ehrlich und respektvoll vorzugehen, auch um das allgemeine Vertrauen in Forschung und Wissenschaft zu stärken. Sie können als Orientierung im Rahmen wissenschaftlicher Arbeitsprozesse geltend gemacht werden.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Handwritten Text Recognition (HTR) bezeichnet die automatische Erkennung von Handschriften. Der Scan der Handschrift wird maschinell erfasst und in einen elektronischen Text umgeformt. Die Automatisierung beruht auf dem Erkennen von Mustern und Gesetzmäßigkeiten, dem so genannten maschinellen Lernen (forTEXT). Die automatische Texterkennung von gedruckten oder maschinengeschriebenen Werken wird Optical Character Recognition (OCR) genannt. | |
|---|---|
| Verwandte Glossareinträge | |
„Informierte Einwilligung (informed consent) meint die Zustimmung der Forschungsteilnehmenden zur Teilnahme an einem Forschungsvorhaben auf der Basis umfangreicher und verständlicher Informationen. Die Ausgestaltung einer informierten Einwilligung muss dabei sowohl ethische Grundsätze als auch datenschutzrechtliche Anforderungen adressieren.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Eine Integrated Development Environment (IDE) – zu deutsch Integrierte Entwicklungsumgebung – ist eine Software, die verschiedene zur Entwicklung von Programmen notwendige Tools in einem Paket vereint. IDEs bieten Unterstützung beim Schreiben von Programmen, beim Übersetzen in Maschinensprache sowie beim anschließenden Ausführen und Fehlersuchen. Sie unterstützen zudem oft die Verwendung von Versionskontrollsystemen direkt aus der IDE heraus. Der konkrete Funktionsumfang ist von IDE zu IDE verschieden, so unterstützen manche nur eine Programmiersprache, während andere ein möglichst breites Spektrum unterschiedlicher Sprachen abdecken. |
|---|
„Unter Interoperabilität bezeichnet man die Fähigkeit eines Systems mit anderen Systemen nahtlos zusammenzuarbeiten. Innerhalb interoperabler Systeme können Daten automatisiert mit anderen Datensätzen kombiniert und ausgetauscht werden. Somit werden Daten auf vereinfachte und beschleunigte Weise maschinell lesbar, interpretierbar und vergleichbar. Interoperabilität stellt eines der Hauptkriterien der FAIR-Prinzipien dar (Forschungsdaten.info 2026).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Ein kontrolliertes Vokabular ist eine Sammlung von Begriffen in einem bestimmten Kontext, das nach festgelegten Regeln erstellt wird, um Eindeutigkeit zu gewährleisten. Kontrollierte Vokabulare reichen von einfachen Wortlisten wie Normdaten bis zu komplexeren strukturierten Vokabularen wie Taxonomien, Klassifikationen und Thesauri.“ (Petersen et al. 2025, 7) | |
|---|---|
| Verwandte Glossareinträge | |
Künstliche Intelligenz (KI), im Englischen Artificial Intelligence (AI), „ist ein Teilgebiet der Informatik. Sie imitiert menschliche kognitive Fähigkeiten, indem sie Informationen aus Eingabedaten erkennt und sortiert“ (Fraunhofer-Institut für Kognitive Systeme IKS o. D.). Durch technische Fortschritte in der verfügbaren Hardware und der Weiterentwicklung von Algorithmen des maschinellen Lernens haben sich die Fähigkeiten von KI in den letzten Jahren erheblich verbessert. Sie findet produktiven Einsatz beispielsweise im autonomen Fahren, der Steuerung von Fabriken und der Medizin (Fraunhofer-Institut für Kognitive Systeme IKS o. D.). Durch die neu aufgekommenen Large Language Models sind mächtige KI-basierte Werkzeuge zum Umgang mit Text entstanden. Weitere Einsatzgebiete sind auch die Erstellung und die Verarbeitung von Bildmaterial. | |
|---|---|
| Verwandte Glossareinträge | |
Large Language Models (LLM), große Sprachmodelle im Deutschen, sind eine Technik aus dem Bereich des Machine Learning. Es handelt sich um „leistungsstarke Modelle, die darauf ausgelegt sind, menschliche Sprache zu verstehen und zu generieren. Sie können Text analysieren und verstehen, kohärente Antworten generieren und sprachbezogene Aufgaben ausführen“ (Jöckel, Kelbert, und Siebert 2023). Ihre Fähigkeiten erhalten sie einerseits durch ihre Architektur und andererseits durch die schiere Menge ihrer Trainingsdaten. Auf wie viele Erkenntnisse aus ihrem Trainingsprozess die Modelle während der Ausführung zurückgreifen können, wird u. a. durch die Anzahl ihrer Parameter bestimmt. Aufgrund der notwendigen Rechenleistung zur Ausführung ist i. d. R. spezialisierte Hardware notwendig. LLMs können Teil einer Pipeline sein, um Informationen auszuwerten und beispielsweise durch Nutzung zusätzlicher Quellen Antworten zu generieren. Problematisch bleibt, dass LLMs kein Konzept von Korrektheit kennen und ihre eigenen Aussagen nur begrenzt auf Richtigkeit prüfen können, wodurch sie zu sog. Halluzinationen neigen (Naveed et al. 2024). | |
|---|---|
| Verwandte Glossareinträge | |
„Leistungsschutzrechte sind verwandte Schutzrechte im Urheberrecht. Sie schützen nicht das Werk an sich, sondern die künstlerische, wissenschaftliche Leistung von Personen oder eine getätigte Investition. Letzteres gilt vor allem für die Erstellung von Datenbanken oder die Produktion von Filmen. Eine künstlerische oder wissenschaftliche Leistung kann die Aufführung eines Theaterstücks sein, die Übersetzung eines Werkes oder die Erstellung eines Lichtbildes, z. B. eines Fotos oder einer Röntgenaufnahme. Das Urheberrecht (UrhG) sieht folgende verwandte Schutzrechte vor (§§ 70-94) (UrhG 2021):
| |
|---|---|
| Verwandte Glossareinträge | |
„Ligatur ist ein Begriff aus der Typografie und bezeichnet die Verbindung von zwei und mehr Buchstaben zu einer Einheit und damit eigenständigen Zeichen“ (o. A. 2024).  Grafik: Ligatur, Anne Voigt, lizenziert unter CC-BY-4.0 |
|---|
„In einem Lizenzvertrag oder über eine offene Lizenz legen die Rechteinhabenden fest, wie und unter welchen Bedingungen das eigene urheberrechtlich geschützte Werk durch Dritte verwendet und oder verwertet werden darf. Kommerzielle Einrichtungen wie etwa Verlage schließen i. d. R. Lizenzverträge mit den Urheberrechtsinhabenden ab. Werden diese Werke dann von Dritten weitergenutzt, müssen sie eine Erlaubnis zur Nutzung beim Nutzungsrechtsinhabenden (in diesem Fall dem Verlag) einholen und ggf. eine Lizenzgebühr bezahlen. Offene Lizenzen, wie die Creative-Commons-Lizenzen, gestatten hingegen eine kostenlose Nutzung. Werden offen lizenzierte Forschungsdaten von Dritten genutzt „kommt automatisch ein Vertrag zwischen dem Lizenzgeber und dem Lizenznehmer zustande, ohne, dass es dafür eines Kontakts zwischen ihnen bedarf“ (Universitätsbibliothek Technische Universität München 2023, 5).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Machine Learning, bzw. maschinelles Lernen im Deutschen, ist ein Teilbereich der künstlichen Intelligenz. Auf Grundlage möglichst vieler (Text-)Daten erkennt und erlernt ein Computer die häufig sehr komplexen Muster und Gesetzmäßigkeiten bestimmter Phänomene. Daraufhin können die aus den Daten gewonnen Erkenntnisse verallgemeinert werden und für neue Problemlösungen oder für die Analyse von bisher unbekannten Daten verwendet werden.“ (Glossar forTEXT) | |
|---|---|
| Verwandte Glossareinträge | |
Markdown ist eine Auszeichnungssprache für Text. Es können grundlegende Formatierungen wie Überschriften, Aufzählungen, Tabellen etc. ausgezeichnet werden. Ziel von Markdown ist es, leicht les- und erstellbar zu sein. Softwareentwicklungsplattformen wie GitHub oder GitLab nutzen Markdown beispielsweise für die Formatierung von ReadMe-Dateien und Projekt-Wikis.  …wird in Editoren grafisch dargestellt als: Überschrift erster EbeneMarkdown ermöglicht die Auszeichnung von Text beispielsweise als kursiv und fett.
| |
|---|---|
| Verwandte Glossareinträge | |
„Metadaten sind Beschreibungen von Forschungsdaten (Daten über Daten) und geben inhaltliche und strukturierte Informationen zum Forschungskontext, dem methodischen und analytischen Verfahren, sowie über das jeweilige Forschungsteam, das die Daten generiert. Sie lassen sich unterscheiden in bibliographische, administrative, prozessuale und deskriptive Metadaten und werden beispielsweise in Form von Templates, ReadMe-Dateien oder Data Curation Profiles verfasst. Metadaten werden begleitend zu den Forschungsdaten selbst publiziert und gelten insbesondere in Online-Repositorien und Forschungsdatenzentren als unverzichtbar für das Nachvollziehen und Verstehen von Datensätzen durch Dritte. Auch erleichtern Metadaten die Auffindbarkeit und Maschinenlesbarkeit von Daten und sind somit Teil der FAIR-Prinzipien und der guten wissenschaftlichen Praxis.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Ein Metadatenschema gibt verpflichtende Vorgaben, wie Metadaten strukturiert sein sollen. Festgelegt werden Elemente der Beschreibung von Forschungsdaten und in welchem Format diese vorliegen sollen. Auf diese Weise werden Metadaten standardisiert und reguliert, was zu einer erhöhten Maschinenlesbarkeit, Vergleichbarkeit und einer automatisierten Datenverwendung und -erfassung beiträgt. | |
|---|---|
| Verwandte Glossareinträge | |
„Metadatenstandards dienen der einheitlichen Beschreibung von ähnlichen Daten durch Metadaten. Sie legen die Begriffe und Bedeutungen, sowie Struktur und Aufbau als Standard für z. B. eine bestimmte Fachdisziplin fest. Metadatenstandards fördern so die Auffindbarkeit von Daten und unterstützen die Interoperabilität zwischen Anwendungen, also den Austausch, den Vergleich und die Verknüpfung von Datensätzen7 Ein verbreiteter Metadatenstandard ist der Dublin Core (siehe folgendes Beispiel: https://www.dublincore.org/specifications/dublin-core/dcmi-terms/)..“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Eine Nachnutzung, oftmals auch Sekundärnutzung genannt, befragt bereits erhobene und veröffentlichte Forschungsdatensätze erneut mit dem Ziel, andere Erkenntnisse, möglicherweise aus einer neuen oder unterschiedlichen Perspektive, zu erhalten. Die Aufbereitung von Forschungsdaten für eine Nachnutzung erfordert einen erheblich höheren Anonymisierungs-, Aufbereitungs- und Dokumentationsaufwand als die bloße Archivierung im Sinne von Datenspeicherung.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Eine Named Entity (NE) ist eine benannte Entität, oft ein Eigenname, die meist in Form einer Nominalphrase zu identifizieren ist. Named Entities können beispielsweise Personen wie „Nils Holgerson”, Organisationen wie „WHO” oder Orte wie „New York” sein. Named Entities können durch das Verfahren der Named Entity Recognition (NER) automatisiert ermittelt werden (forTEXT o. D.). | |
|---|---|
| Verwandte Glossareinträge | |
Natural Language Processing (NLP), maschinelle Sprachverarbeitung zu Deutsch, ist ein Teilgebiet der Linguistik, der Informatik und der künstlichen Intelligenz, welches sich damit beschäftigt, wie Computer so programmiert werden, dass sie große Mengen an natürlichsprachlichen Daten verarbeiten und analysieren können. |
|---|
„Normdaten bilden Identifikationen und standardisierte normierte Datensätze in Form von eindeutigen Nummern, anhand derer Personen, Werke, Institutionen, Forschungsförderer, Körperschaften oder Schlagwörter eindeutig beschrieben und zuordenbar werden. Eine fälschliche oder doppelte Zuordnung entfällt durch diese normierten Daten. Insbesondere in Katalogen und Datenbanken können durch Normdaten Informationen zu bestimmten Entitäten vereinfacht herausgefunden werden, wodurch eine digitale Vernetzung und Auffindbarkeit zwischen Projekten stattfinden kann. Die „Gemeinsame Normdatei“ (GND) der Deutschen Nationalbibliothek ist in Deutschland die zentrale Normdatei8 siehe: https://www.dnb.de/DE/Professionell/Standardisierung/GND/gnd_node.html.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Open Access bezeichnet den freien, kostenlosen, ungehinderten und barrierefreien Zugang zu wissenschaftlichen Erkenntnissen und Materialien. Für eine weitere rechtssichere Nachnutzung der Materialien durch Dritte müssen die Urhebenden mittels Lizenzvertrages die Nutzungsrechte an ihren Werken einräumen. Die freien CC-Lizenzen spezifizieren bspw. genau, wie Daten und Materialien weitergenutzt werden dürfen. Bei der Veröffentlichung von wissenschaftlichen Inhalten gibt es zwei Wege: Der goldene Weg bezeichnet die Open-Access-Erstveröffentlichung von wissenschaftlichen Texten meist in Monografien o. Ä., der grüne Weg die Zweitveröffentlichung auf institutionellen Repositorien oder Webseiten der Autor*innen (Open-Access Network 2023).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Open Data (offene Daten) sind Daten, die offen und frei online zugänglich sind sowie uneingeschränkt von Dritten weiterverwendet werden dürfen. Dies setzt voraus, dass sie mit einer offenen Lizenz versehen sind (Opendefinition 2023).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Der Begriff Open Science bündelt … Strategien und Verfahren, die allesamt darauf abzielen, … alle Bestandteile des wissenschaftlichen Prozesses über das Internet offen zugänglich und nachnutzbar zu machen. Damit sollen Wissenschaft, Gesellschaft und Wirtschaft neue Möglichkeiten im Umgang mit wissenschaftlichen Erkenntnissen eröffnet werden“ (Open Science AG 2014). „Publikationen, Forschungsdaten oder Codes werden zunehmend von Wissenschaftler*innen unter den Begriffen Open Access, Open Data, Open Source u. a., die alle unter dem Sammelbegriff Open Science subsumiert werden, frei im Web zugänglich gemacht.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Die Open-Science-Bewegung plädiert seit den frühen 2000er Jahren für eine offene und transparente Wissenschaft, in der alle Schritte des wissenschaftlichen Erkenntnisprozesses offen online zugänglich gemacht werden. So sollen nicht nur Endergebnisse von Forschungen wie Monographien oder Artikel öffentlich geteilt werden, sondern auch verwendete Materialien, die den Entstehungsprozess begleiteten wie: Labortagebücher, Forschungsdaten, verwendete Software, Forschungsberichte usw. Dadurch soll eine Partizipation an Wissenschaft und Erkenntnissen gefördert und interessierte Öffentlichkeiten angesprochen werden. Kreativität, Innovation und neue Kollaborationen sollen gefördert, Erkenntnisse auf ihre Qualität, Richtigkeit und Authentizität hin überprüft werden, was eine Demokratisierung von Forschung bezwecken soll. Zur Open Science zählen u. a. Open Access und Open Data, die Infrastrukturen des Teilens von Zwischenergebnissen von Forschungen bilden.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Optical Character Recognition (OCR) bezeichnet die automatische Texterkennung von gedruckten oder maschinengeschriebenen Werken. Der Scan des Durckwerks wird maschinell erfasst und in einen elektronischen Text umgeformt. Die Automatisierung beruht auf dem Erkennen von Mustern und Gesetzmäßigkeiten, dem so genannten maschinellen Lernen. Die automatische Erkennung von Handschriften wird Handwritten Text Recognition (HTR) genannt. | |
|---|---|
| Verwandte Glossareinträge | |
Die Open Research and Contributor-ID (ORCID) ist ein international anerkannter persistenter Identifikator, mit dessen Hilfe Forschende eindeutig identifiziert werden können. Die ID kann dauerhaft sowie institutionsunabhängig von Forschenden für ihre wissenschaftlichen Veröffentlichungen verwendet werden. Sie besteht aus 16 Ziffern, die in vier Viererblöcken dargestellt sind (z.B. 0000-0002-2792-2625). Die ORCID-ID ist als Identifizierungsnummer bei zahlreichen Verlagen, Universitäten und wissenschaftsnahen Einrichtungen etabliert und wird in den Workflow z. B. bei der Begutachtung von Zeitschriftenartikeln integriert9 Eine ORCID kann unter https://orcid.org/ kostenfrei erstellt werden.. | |
|---|---|
| Verwandte Glossareinträge | |
Personenbezogene Daten sind: „alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person (betroffene Person) beziehen; als identifizierbar wird eine natürliche Person angesehen, die direkt oder indirekt, insbesondere mittels Zuordnung zu einer Kennung wie einem Namen, zu einer Kennnummer, zu Standortdaten, zu einer Online-Kennung oder zu einem oder mehreren besonderen Merkmalen, die Ausdruck der physischen, physiologischen, genetischen, psychischen, wirtschaftlichen, kulturellen oder sozialen Identität dieser Person sind, identifiziert werden kann;…“ (EU-DSGVO, Artikel 4 Nr. 1; BDSG, §46 Abs. 1; BlnDSG, §31). | |
|---|---|
| Verwandte Glossareinträge | |
„Ein Persistent Identifier (PID) (auf Deutsch: dauerhafter Identifikator) ist ein dauerhafter, digitaler Code, der einer digitalen Ressource wie z. B. einem Datensatz, einem wissenschaftlichen Artikel oder einer anderen Veröffentlichung direkt zugeordnet ist und diese damit permanent identifizier- und auffindbar macht. Im Gegensatz zu anderen seriellen Identifikatoren (bspw. URL-Adressen) verweist ein Persistent Identifier auf das Objekt selbst und nicht auf seinen Standort im Internet. Ändert sich der Standort eines mit einem Persistent Identifier assoziierten digitalen Objekts, so bleibt der Identifikator derselbe. Es muss lediglich in der Identifikator-Datenbank der URL-Standort geändert oder ergänzt werden. So wird sichergestellt, dass ein Datensatz dauerhaft auffindbar, abrufbar und zitierbar bleibt (Forschungdaten.info 2023). PIDs spielen eine zentrale Rolle bei der FAIRen (Wieder)Verwendung von Forschungsdaten und werden nicht ohne Grund explizit in den FAIR-Prinzipien erwähnt. Forschungsdaten sollten zugänglich, interoperabel und wiederverwendbar sein, aber dazu müssen sie zuerst auch gefunden werden. Global eindeutige und persistente Identifier sind unerlässlich, um die Identifikation veröffentlichter Ressourcen zu ermöglichen und maschinenlesbare Metadaten bereitzustellen. PIDs werden jedoch nicht nur Datensätzen und Publikationen zugeordnet, sondern sind für alle Aspekte des Forschungsdatenlebenszyklus relevant, für die Forschenden selbst, sowie Organisationen und Förderinstitutionen. Beispiele für persistente Identifikatoren sind z. B. der DOI oder die ORCID.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Pre-Processing, auf Deutsch Vorverarbeitung umfasst bei digitalen Dokumenten verschiedene Schritte mit häufig automatisierten Verfahren. Sie hängen von der Art der Daten ab, die vorverarbeitet werden müssen. In der Regel sind die folgenden Schritte enthalten: Bereinigung, Normalisierung, Layoutkorrektur und Formatierungsanpassungen. Insgesamt zielt Pre-Processing darauf ab, die Qualität der Daten zu verbessern, mit denen man arbeitet“ (o. A. 2024). |
|---|
Programmbibliothek, kurz Bibliothek, wird in der Informatik eine Sammlung von Funktionen genannt, die in anderen Programmen eingebunden und von diesen verwendet werden kann. Eine Funktion ist in diesem Kontext ein in sich abgeschlossener Programmcode, der von anderen Stellen eines Programms aus aufgerufen und ausgeführt werden kann. Für Programmiersprachen wie Python gibt es eine ausgesprochen umfangreiche Sammlung von Bibliotheken, die komplexe Funktionalitäten z. B. für das Machine Learning bieten. |
|---|
„Proprietäre Dateiformate sind Dateiformate, die sich nicht oder nur mit Schwierigkeiten von Dritten öffnen bzw. lesen lassen, da sie z. B. lizenzrechtlich oder durch Patente geschützt sind. Meist wird dafür spezielle (kostenpflichtige) Software benötigt (Wikipedia 2023). Beispiele hierfür sind z. B. das Wordformat .docx oder das Adobe Photoshop-Format .psd.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Die Pseudonymisierung ist „die Verarbeitung personenbezogener Daten in einer Weise, in der die personenbezogenen Daten ohne Hinzuziehung zusätzlicher Informationen nicht mehr einer spezifischen betroffenen Person zugeordnet werden können, sofern diese zusätzlichen Informationen gesondert aufbewahrt werden und technischen und organisatorischen Maßnahmen unterliegen, die gewährleisten, dass die personenbezogenen Daten nicht einer identifizierten oder identifizierbaren natürlichen Person zugewiesen werden können“ (BlnDSG, §31; EU-DSGVO, Artikel 4 Nr. 5). Übliche Strategien sind der Ersatz des Eigennamens (durch einen Buchstaben oder einen anderen Namen) oder die Verschleierung der Forschungsorte durch die Nennung fiktiver Ortsnamen. Oft werden auch die Forschungsregionen nicht expliziert.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
ReadMe-Dateien (oft auch Readme geschrieben) im Kontext von Systemen oder Projekten enthalten überblicksartige Informationen zum jeweiligen System, Projekt o. ä., damit die Nutzenden sich schneller zurechtfinden. ReadMe-Dateien dokumentieren die grundlegenden Eigenschaften, z. B. wozu das jeweilige System oder Projekt genutzt werden kann und wo eine weiterführende Dokumentation zu finden ist. Welche konkreten Inhalte in einer ReadMe-Datei enthalten sind, hängt stark vom jeweiligen Einsatzzweck und dem antizipierten Rezipientenkreis ab, also auch, ob diese für die Öffentlichkeit bestimmt sind oder interne Projekte dokumentieren. ReadMe-Dateien im Kontext von Forschungsdaten enthalten Informationen über Forschungsdaten, Forschungsdatensätze oder Forschungsdatensammlungen in kompakter und strukturierter Form. ReadMe-Dateien können als Begleitdokumente zu Forschungsdaten veröffentlicht oder zur Dokumentation der strukturierten Speicherung von Forschungsdaten am Ende eines Projekts verwendet werden (z. B. auf einem Institutsserver oder Repositorium zur Archivierung). ReadMe-Dateien sammeln zentrale Metadaten über das Projekt, in dem die Daten entstanden sind (wie Projektname, beteiligte Personen, Finanzierung), geben Auskunft über Ordnerstrukturen, Abkürzungen und Normdaten und halten Änderungen und Versionierungen von Forschungsdaten fest (Forschungsdaten.info 2026). ReadMe-Dateien sind oft als einfache Textdateien oder im Markdown-Format abgelegt. Prinzipiell können ReadMe-Dateien in jedem beliebigen Format abgelegt werden. Da sie jedoch die erste Anlaufstelle für Informationen über ein Projekt sind, sollten sie möglichst keine spezielle Software zum Öffnen benötigen und unter jedem Betriebssystem gelesen werden können, wozu reine Textdateien am besten geeignet sind. Markdown ist ein Format, das ebenfalls reine Textdateien erzeugt, welches jedoch Steuerzeichen wie bspw. das Rautensymbol enthält, um z. B. Überschriften auszuzeichnen. Da viele Plattformen zum Verwalten von (Software)projekten wie bspw. GitLab oder GitHub das Anzeigen von so formatierten Textdateien unterstützen, hat sich Markdown als ein de facto Standard für ReadMe-Dateien etabliert. Vorteilhaft ist dabei, dass es sich weiterhin um reine Textdateien handelt, deren Inhalt auch ohne Verarbeiten der Markdown-Elemente verstanden werden kann. | |
|---|---|
| Verwandte Glossareinträge | |
„Das Recht am eigenen Bild besagt, dass jede Person selbst entscheiden kann, ob und wo sein Bild veröffentlicht wird. Für eine Verbreitung und Veröffentlichung eines Fotos mit hierauf erkennbaren Personen bedarf es sowohl in Printmedien als auch im Internet nach §22 des Kunsturhebergesetzes der Zustimmung der abgebildeten Person10 Zum genauen Gesetztext siehe Kunsturhebergesetzes (KUG) unter: https://www.gesetze-im-internet.de/kunsturhg/__22.html.“ (Data Affairs, Glossar) |
|---|
„Ein Repositorium bildet einen Ort der Aufbewahrung wissenschaftlicher Dokumente. In Online-Repositorien werden Publikationen digital gespeichert, verwaltet und mit persistenten Identifikatoren versehen. Die Katalogisierung vereinfacht die Suche und Nutzung von Publikationen und Autor*innen. In den meisten Fällen sind Dokumente in Online-Repositorien uneingeschränkt und offen zugänglich (Open Access).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Die Schöpfungshöhe, Gestaltungshöhe oder auch Werkhöhe ist ein Kriterium im Urheberrecht, mit dem die Schutzwürdigkeit eines Werkes beurteilt wird. Sie ist kein fest definierter Rechtsbegriff, sondern muss anhand jedes Werkes neu beurteilt werden. Verfügt ein Werk über ausreichend Originalität, Individualität bzw. künstlerische Qualität, gilt es als eigenständige Schöpfung, verfügt damit über die Schöpfungshöhe und unterliegt dem urheberrechtlichen Schutz. In Abgrenzung dazu gelten Werke, die keine Schöpfungshöhe aufweisen, als gemeinfrei.“ (Glossar zur Lernzielmatrix 2025) | |
|---|---|
| Verwandte Glossareinträge | |
„Einen eigenen Teilbereich innerhalb der personenbezogenen Daten bilden die sog. besonderen Kategorien personenbezogener Daten. Ihre Definition geht auf den EU-DSGVO Artikel 9 Abs. 1, 2016 zurück, der besagt, dass es sich hierbei um Angaben über
der Betroffenen handelt. Hierunter fallen auch genetische und biometrische Daten (z. B. Fingerabdruck) zur Identifizierung einer natürlichen Person. Laut Datenschutz-Grundverordnung gelten diese Angaben als „sensibel“, weil ihre Erhebung, Verarbeitung oder Nutzung erhebliche Risiken für die Betroffenen mit sich bringen kann. Sie unterliegen daher besonderen Pflichten und Verarbeitungsbedingungen. Grundsätzlich gilt, dass zur Verarbeitung personenbezogener Daten das Einverständnis der betroffenen Personen einzuholen ist. Ausnahmen gelten, wenn die Daten von der betroffenen Person selbst öffentlich gemacht wurden oder ein erhebliches öffentliches Interesse besteht (EU-DSGVO Artikel 9 Abs. 2, 2016). Gerade in ethnografischen Forschungsvorhaben entstehen regelmäßig personenbezogene Daten, die laut Datenschutz-Grundverordnung in hohem Maße als sensibel gelten.“ (Data Affairs, Glossar) | |
|---|---|
| Synonyme Glossareinträge | |
| Verwandte Glossareinträge | |
„Forschungsdaten und besonders sensible Daten sollten vor fremden Zugriff geschützt werden. Sichere, also starke und individuelle Passwörter, deren Entschlüsselung viel Zeit und Rechenleistung erfordern, sind hierfür ein wichtiger Baustein. Generell kann gesagt werden, je höher die Komplexität des Passworts, desto sicherer ist es. Tipps zur Passwortgenerierung:
| |
|---|---|
| Verwandte Glossareinträge | |
„Das sichere Löschen von digitalen Forschungsdaten geht über ein Verschieben in den digitalen Papierkorb hinaus, denn mit diesem Vorgang werden nur die Verweise auf die Daten gelöscht, nicht die Daten selbst. Um Daten ganz sicher zu löschen, sollten spezielle Programme zum Schreddern von Daten verwendet werden, Daten mit sinnlosen Daten überschrieben werden bzw. der Datenträger selbst zerstört werden (BSI 2023b).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Moderne Softwareentwicklung findet in aller Regel über speziell dafür entwickelte Plattformen statt, die Methoden zum Projektmanagement und der Verwaltung des Quellcodes bieten. Für Letzteres hat sich das Tool git als De-Facto-Standard etabliert. Softwareentwicklungsplattformen bieten die Möglichkeit, die Entwicklung projektzentriert durchzuführen und neben dem Quellcode beispielsweise ein Wiki zu pflegen und Fehler mittels eines Issue-Trackers nachzuverfolgen. Über diesen können auch Nutzer*innen von Software Fehler melden. Diese Plattformen bieten auch weitere Mechanismen zur Automatisierung, z. B. das automatische Erstellen von lauffähigen Programmen aus dem Quellcode, die dann zum Herunterladen angeboten werden können. Bekannte Beispiele für solche Plattformen sind GitHub11siehe unter: https://github.com, ein proprietärer Dienst von Microsoft, und GitLab12siehe unter: https://gitlab.com, welches auch auf eigenen Servern gehostet werden kann, was u. a. an vielen Universitäten erfolgt. | |
|---|---|
| Verwandte Glossareinträge | |
2Supplemente (zu wissenschaftlichen Veröffentlichungen) sind Materialien und Forschungsdaten, die ergänzend zu einer wissenschaftlichen Veröffentlichung publiziert werden, da in den Journal-Artikeln die Auswertung der Datenerhebung und Forschungsergebnisse meist nur in zusammengefasster Form erfolgen kann. Die Supplemente können detaillierte Erläuterungen enthalten, die Datensätze selbst, oder weiterführenden Informationen, die den Kontext der erhobenen Daten näher erläutern und fördern somit die Transparenz und Reproduzierbarkeit von Materialien und Forschungsdaten.“ (Data Affairs, Glossar) |
|---|
TEI (Text Encoding Initiative) bezeichnet sowohl eine Organisation13siehe unter: https://tei-c.org/ als auch ein gleichnamiges Dateiformat. Letzteres basiert auf XML (Extensible Markup Language), einer weit verbreiteten Auszeichnungssprache, und hat sich in den Geisteswissenschaften als Standard zur Kodierung und Auszeichnung von Texten durchgesetzt. Mit Hilfe von TEI ist es möglich, maschinenlesbar Elemente eines Textes auszuzeichnen, wie beispielsweise Absätze oder Überschriften.14Die Spezifikation von TEI – auch Guidelines genannt – kann unter https://tei-c.org/release/doc/tei-p5-doc/en/html/index.html eingesehen werden. Zudem können Inhalte wie Personen- oder Ortsnamen als solche markiert und Anmerkungen eines kritischen Apparates eingefügt werden. Im Hinblick auf das Forschungsdatenmanagement ist es vorteilhaft, dass es sich bei TEI um ein Nur-Text-Format handelt, es also auch ohne spezielle Programme von Menschen interpretiert werden kann. | |
|---|---|
| Verwandte Glossareinträge | |
„Das Topic Modeling ist ein statistisches, auf Wahrscheinlichkeitsrechnung basierendes, Verfahren zur thematischen Exploration größerer Textsammlungen. Das Verfahren erzeugt „Topics“ zur Abbildung häufig gemeinsam vorkommender Wörter in einem Text.“ (forTEXT) |
|---|
„Das Urheberrecht (UrhG) schützt bestimmte geistige Schöpfungen (Werke) und Leistungen. Unter Werke fallen Sprachwerke, Lichtbild-, Film- und Musikwerke sowie Darstellungen wissenschaftlicher oder technischer Art, wie Zeichnungen, Pläne, Karten, Skizzen, Tabellen und plastische Darstellungen (Gesetz über Urheberrecht und verwandte Schutzrechte 2021, §2). Die künstlerischen, wissenschaftlichen Leistungen von Personen oder die getätigte Investition gelten dagegen als schützenswerte Leistungen (Leistungsschutzrecht). | |
|---|---|
| Verwandte Glossareinträge | |
Eine Variable bezeichnet im Kontext der Informatik einen mit einem Namen belegten Platzhalter, vergleichbar der Nutzung in der Mathematik. Eine Variable ist mit einem Bereich im Arbeitsspeicher des Computers verknüpft, in der dann der Wert dieser Variablen steht. Der Wert kann während der Ausführung des Programms verändert werden. | |
|---|---|
| Verwandte Glossareinträge | |
„Der Begriff der „Verarbeitung“ ist definiert als „jeden mit oder ohne Hilfe automatisierter Verfahren ausgeführten Vorgang oder jede solche Vorgangsreihe im Zusammenhang mit personenbezogenen Daten wie das Erheben, das Erfassen, die Organisation, das Ordnen, die Speicherung, die Anpassung oder Veränderung, das Auslesen, das Abfragen, die Verwendung, die Offenlegung durch Übermittlung, Verbreitung oder eine andere Form der Bereitstellung, den Abgleich oder die Verknüpfung, die Einschränkung, das Löschen oder die Vernichtung;“ (BlnDSG, §31; EU-DSGVO, Artikel 4 Nr. 2). Die Verarbeitung bezeichnet also jegliche Form der Arbeit mit personenbezogenen Daten, von der Erhebung bis zur Löschung.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
„Versionierung bedeutet die Erfassung aller Veränderungen von Forschungsdaten während des Arbeitsprozesses. Es empfiehlt sich bei jeder Datenanpassung eine neue Version dieser zu speichern, um die Veränderung nachvollziehbar kenntlich zu machen. Dafür können manuelle Maßnahmen wie Versionierungsschemata (z. B. durch Nummerierung: Version 1.3.2.) ergriffen, oder Versionierungssoftware wie Git verwendet werden. Versioniert wird während des Forschungsprozesses selbst, aber auch bei bereits veröffentlichten Forschungsdaten ist eine Versionierung im Nachhinein möglich, um nachnutzenden Dritten die korrekte Version der Forschungsdaten zur Verfügung zu stellen.“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Ein Versionskontrollsystem ist ein Programm, das zur Versionierung von Dateien genutzt wird. Jeder Änderungsstand eines Dokuments stellt dabei eine Version dar. Ein Versionskontrollsystem wird oft zur Verwaltung von Programmcodes eingesetzt, ist aber nicht darauf beschränkt. Jede Art von Dateien kann versioniert werden, dies funktioniert allerdings besonders gut bei Textdateien, da sich dort die Veränderungen zwischen zwei Versionen auch ohne Kenntnisse über das Dateiformat erkennen lassen. Durch Versionierung lassen sich vorhergehende Stände wiederherstellen. Es können zusätzlich abweichende Änderungen zusammengeführt werden, die durch kollaboratives Arbeiten entstanden sind. Zurzeit ist die Software git das dominierende Versionskontrollsystem. Sie ist integraler Bestand von Softwareentwicklungsplattformen wie GitHub und GitLab. Ein mittels git versioniertes Projekt kann also leicht über diese Plattformen zugänglich gemacht werden. | |
|---|---|
| Verwandte Glossareinträge | |
Wikidata ist eine internationale, kollaborative Wissensdatenbank, die eng mit Wikipedia verknüpft ist und auf deren Konzept der Wissenssammlung aufbaut. Sie kann als Normdatei verwendet werden. Viele Einträge sind zudem mit weiteren Ressourcen verknüpft und verweisen beispielsweise auf zugehörige Einträge in der GND. | |
|---|---|
| Verwandte Glossareinträge | |
„ALTO, auf Deutsch „Analysiertes Layout und Textobjekt“ ist ein XML-Standard für die Darstellung des physischen Layouts und der logischen Struktur von Text, der mit OCR oder HTR transkribiert wurde. Es behält alle geometrischen Koordinaten des Inhalts (Text, Illustrationen, Grafiken) im Bild bei und ermöglicht die Überlagerung von Bild und Text.“ (o. A. 2024) | |
|---|---|
| Verwandte Glossareinträge | |
„PAGE, auf Deutsch „Seitenanalyse und Ground Truth Elemente“, ist ein XML-Standard für die Kodierung digitalisierter Dokumente. Er ist mit dem ALTO-Format vergleichbar und kann verwendet werden, um die Struktur einer Seite und ihren Inhalt darzustellen.“ (o. A. 2024) | |
|---|---|
| Verwandte Glossareinträge | |
„In Archiven oder Repositorien regeln Zugriffsrechte, welche Personen in welchem Umfang Zugang und Einsicht in Datenmaterial zur Nachnutzung bekommen. I. d. R. wird unterschieden zwischen einem
|
|---|
„Die Verarbeitung personenbezogener Daten darf nur zu festgelegten und eindeutigen Zwecken erfolgen. Diese sollten möglichst schon vor der Erhebung so präzise wie möglich bestimmt werden und im Forschungsvorhaben – wenn möglich – in einer Einwilligungserklärung hinterlegt werden. Weitere Verarbeitungsschritte sind an diesen Zweck gebunden. Ändern oder erweitern sich Zwecke während des Forschungsvorhabens, wenn sich z. B. bei der Analyse der Forschungsdaten neue Fragestellungen ergeben, muss ggf. erneut eine Einwilligung der betroffenen Personen eingeholt werden. Die Daten sind zu löschen, sobald der Zweck erreicht ist. Personenbezogene Daten dürfen nicht länger als es für die Zwecke erforderlich ist, in einer Form gespeichert werden, die die Identifizierung der betroffenen Personen ermöglicht. Der Umfang der Verarbeitung personenbezogener Daten muss dem Zweck angemessen sein, das bedeutet, so wenig personenbezogene Daten wie nötig und möglich zu erheben und zu verarbeiten (BlnDSG, §32).“ (Data Affairs, Glossar) | |
|---|---|
| Verwandte Glossareinträge | |
Für den Zugriff auf Onlineaccounts und auf manche Hardware wird von den Nutzenden ein Passwort verlangt. Viele Systeme verlangen neben der Passwortabfrage oder PIN zudem einen Zugangscode über externe Systeme (Anruf, SMS oder biometrische Verfahren), um eine zweistufige Überprüfung durchzuführen. Diese Kombination verschiedener Faktoren wird Zwei-Faktor-Authentisierung (2FA) genannt und potenziert den Schutz vor unbefugtem Zugang Dritter. | |
|---|---|
| Verwandte Glossareinträge | |