Vorgehen: Automatische Texterkennung
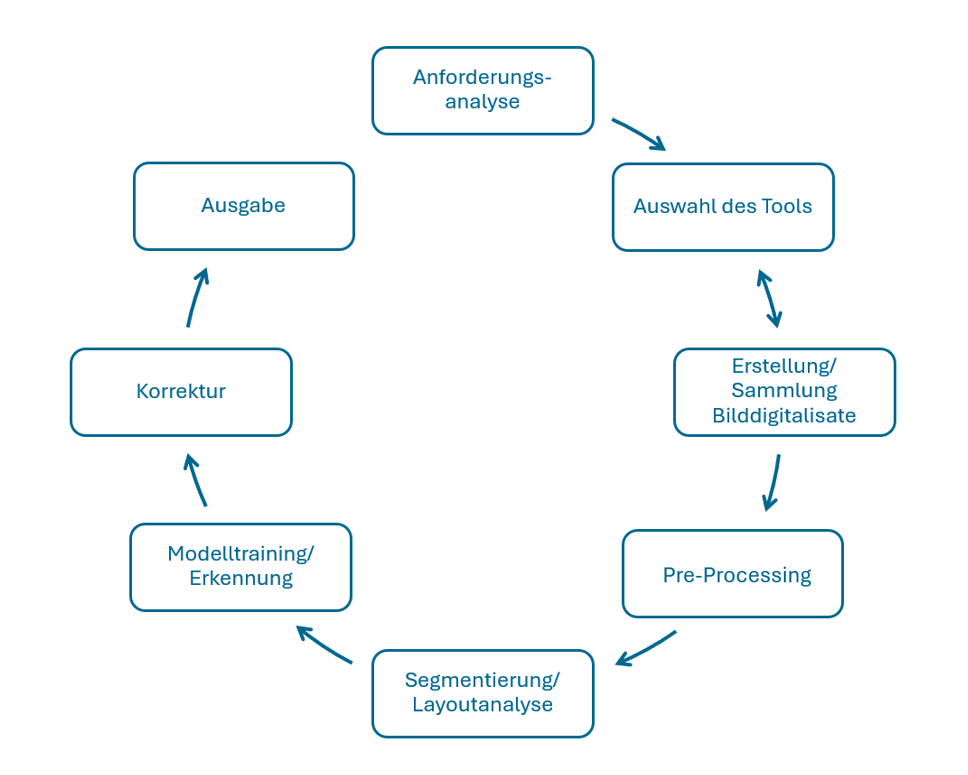
Grafik: Schritte der automatischen Texterkennung (ATR), Anne Voigt, 2026, lizenziert unter CC BY-SA 4.0
- Spezifikation der Anforderungen
Die Ausgangsdaten und das Zielformat entscheiden darüber, welche Funktionen die ATR-Tools haben sollten und somit in die engere Wahl kommen. Daher werden zunächst die Anforderungen in einer Anforderungsanalyse zusammengetragen. Wie ist die Art und Beschaffenheit des Ausgangsmaterials?
– Handelt es sich um handschriftliche Dokumente oder um Druckwerke (Schriftsysteme und verwendete Schriftarten und Formatierungen, vorhandene Annotationen),
– wie ist der Zustand der Daten (z. B. Flecken, Kontrast, Vergilbung …),
– in welchem Format liegen die Daten vor,
– wofür werden die Zieldaten verwendet und
– wie sollen sie ausgegeben werden uvm. (Bach u. a. 2021). - Recherche und Auswahl des Tools (parallel zu Schritt 3)
Für die Recherche und Auswahl passender Tools können noch weitere Aspekte ausschlaggebend sein wie der Funktionsumfang (z. B. verfügbare Modelle und Möglichkeit, eigene Modelle zu trainieren), die Lizenz'In einem Lizenzvertrag oder über eine offene Lizenz legen die Rechteinhabenden fest, wie und unter welchen Bedingungen das eigene urheberrechtlich geschützte Werk durch Dritte verwendet und oder verwertet werden darf. Weiterlesen und damit ggf. anfallende Lizenzkosten, vorhandenes technisches Vorwissen, Aufwand für Installation und Betrieb sowie Handhabbarkeit (Usability), verfügbare Dokumentation oder Supportangebote. Aber auch die Möglichkeit, kollaborativ zu arbeiten, kann die Entscheidung beeinflussen.
Bei einem großen Korpus kann es sich lohnen, die ausgewählten Tools vorab zu testen, um das geeignetste herauszufiltern. Für solche Tests muss nicht zwingend bereits das gesamte Korpus vorliegen. Die Materialien sollten jedoch repräsentativ sein, insbesondere hinsichtlich Seitenaufbau und verwendeter Schriftart, um zuverlässig die Genauigkeit der Ergebnisse der Automatic Text Recognition (ATR) einschätzen zu können. - Sammlung/Erstellung der Bilddigitalisate (parallel zu Schritt 2)
Je nach Ausgangsbedingung müssen die für das Forschungsvorhaben relevanten, bestehenden Bilddigitalisate heruntergeladen oder angefertigt werden. In letzterem Fall ist auf eine entsprechende Qualität zu achten. Die erstellten Scans bzw. Fotografien sollten eine für die Texterkennung hinreichend hohe Auflösung haben. Die Vorlage sollte beim Scannen sorgfältig angeordnet werden, so dass das zu scannende Dokument gerade ausgerichtet und möglichst vollständig ohne Knicke oder Abstände aufliegt, um Verzerrungen beim Ablichten zu vermeiden. Beim Scannen von Büchern kann dies schwierig sein, weshalb viele Buchscanner Algorithmen zur Entzerrung bieten. Hier wäre zu prüfen, ob diese gute Resultate erzielen, so dass verwertbare Bilder entstehen.1Zu technischen Aspekten für gute Digitalisate siehe z. B. Altenhöner u. a. 2023, 15ff.
Wenn die Digitalisate bereits existieren, sollten diese in der höchstmöglichen Auflösungs- und Qualitätsstufe heruntergeladen werden. Faustregel: Je mehr Informationen in einer Bilddatei vorhanden sind, desto besser kann die Software die Inhalte erkennen. Notwendige Reduktionen in der Informationsmenge können immer noch während der weiteren Verarbeitung vorgenommen werden. - Pre-Processing
Ggf. müssen die vorhandenen Digitalisate vor der eigentlichen Texterkennung noch optimiert werden, wenn deren Qualität für den nachfolgenden Prozess nicht ausreicht. Der Schritt dieser Vorverarbeitung umfasst Bildkorrekturen mit einer Bildbearbeitungssoftware wie das Zuschneiden, Drehen, Entzerren und Ausrichten der Vorlagen, um später das bestmögliche Erkennungsergebnis zu erzielen (Souvay und Wil 2024). - Segmentierung/Layoutanalyse
Nach dem Upload der (optimierten) Digitalisate in das Tool analysiert dieses in einem ersten Schritt das Layout des Ausgangsmaterials. Durch die Segmentierung jeder Seite werden die Bereiche ohne Text von Zonen mit Text unterschieden und Textzeilen lokalisiert, um diese später während des Erkennungsvorgangs untersuchen zu können. Je nach Komplexität und Art des Ausgangsmaterials erfolgt dies durch das Tool automatisiert und relativ fehlerfrei oder es wird manuell eingegriffen, indem die Textzonen und -zeilen händisch festgelegt und ggf. auch annotiert werden (Chagué und Scheithauer 2024). - Modelltraining/Erkennung
Nun erfolgt der eigentliche Erkennungsprozess. In diesem Schritt werden aus den Pixeln Buchstaben und Wörter “erkannt” bzw. vielmehr eine wahrscheinliche Buchstabenkombination oder das wahrscheinliche Vorkommen eines Wortes vorhergesagt. Das genaue Vorgehen hängt hierbei von der verwendeten Software und dem darin genutzten Modell ab. Bei Verwendung von ATR-Systemen, die ein Training von Modellen erlauben, wie Transkribus oder eScriptorium, kann es sinnvoll sein, einen Pretest mit möglichst repräsentativem Material durchzuführen, sich die Ergebnisse sowie die Character Error Rate (CER)'Die CER, auf Deutsch 'Zeichenfehlerrate', ist ein Wert zur Bewertung der Genauigkeit der Zeichenerkennung in einer automatischen Transkription auf Zeichenebene. Eine CER von 5 % bedeutet zum Beispiel, dass die automatische Transkription 95 von 100 Zeichen korrekt transkribiert hat' (o. A. 2024). Weiterlesen anzuschauen und Fehler manuell zu korrigieren. Die korrigierten Daten können dann als Trainingsmaterial zur Anpassung des Modells für den restlichen Korpus verwendet werden und so den nachfolgenden Korrekturaufwand minimieren (Pinche und Spychala 2024). - Korrektur
Trotz zuvor trainierter Modelle sind Korrekturen der Ergebnisse notwendig. Diese können halbautomatisch oder manuell erfolgen, wobei letztere die empfohlene Variante ist (Chiffolea und Ondraszek 2024a). - Ausgabe
Je nach Tool und Verwendungszwecken – wie weitere Auszeichnungen und Analysen – wird abschließend das passende Ausgabeformat gewählt. Es gibt reine Textformate, z. B. .txt, oder Exportformate, die alle während der Texterkennung gespeicherten Informationen beinhalten. Diese sogenannten Layout-Formate werden in HTML oder XML kodiert ausgegeben. Die gebräuchlichsten XML-Standards sind PAGE XML'PAGE, auf Deutsch 'Seitenanalyse und Ground Truth Elemente', ist ein XML-Standard für die Kodierung digitalisierter Dokumente. Er ist mit dem ALTO-Format vergleichbar und kann verwendet werden, um die Struktur einer Seite und ihren Inhalt darzustellen.' (o. A. 2024) Weiterlesen und ALTO XML'ALTO, auf Deutsch 'Analysiertes Layout und Textobjekt' ist ein XML-Standard für die Darstellung des physischen Layouts und der logischen Struktur von Text, der mit OCR oder HTR transkribiert wurde. Es behält alle geometrischen Koordinaten des Inhalts (Text, Illustrationen, Grafiken) im Bild bei und ermöglicht die Überlagerung von Bild und Text.' (o. A. 2024) Weiterlesen (Chiffolea und Ondraszek 2024b). Manche Tools erlauben zudem eine Ausgabe als PDF, was vor allem nützlich für eine Durchsuchbarkeit ist, oder es kann ein Export in ein TEITEI (Text Encoding Initiative) bezeichnet sowohl eine Organisationsiehe unter: https://tei-c.org/ als auch ein gleichnamiges Dateiformat. Letzteres basiert auf XML (Extensible Markup Language), einer weit verbreiteten Auszeichnungssprache, und hat sich in den Geisteswissenschaften als Standard zur Kodierung und Auszeichnung von Texten durchgesetzt. Mit Hilfe von TEI ist es möglich, maschinenlesbar Elemente eines Textes auszuzeichnen, wie beispielsweise Absätze oder Überschriften.Die Spezifikation von TEI - auch Guidelines genannt - kann unter https://tei-c.org/release/doc/tei-p5-doc/en/html/index.html eingesehen werden. Zudem können Inhalte wie Personen- oder Ortsnamen als solche markiert und Anmerkungen eines kritischen Apparates eingefügt werden. Im Hinblick auf das Forschungsdatenmanagement ist es vorteilhaft, dass es sich bei TEI um ein Nur-Text-Format handelt, es also auch ohne spezielle Programme von Menschen interpretiert werden kann. Weiterlesen– oder auch Microsoft-Word-Dokument stattfinden.
Literatur
Altenhöner, Reinhard, Andreas Berger, Christian Bracht, Paul Klimpel, Sebastian Meyer, Andreas Neuburger, Thomas Stäcker, und Regine Stein. 2023. DFG-Praxisregeln „Digitalisierung“. Aktualisierte Fassung 2022. Zenodo. https://doi.org/10.5281/zenodo.7435724
Bach, Felix, Stefan Schmunk, Cristian Secco, und Thorsten Wübbena. 2021. „Bomber’s Baedeker – vom Text zum Bild zur Datenquelle“. In Fabrikation von Erkenntnis – Experimente in den Digital Humanities, herausgegeben von Manuel Burghardt, Lisa Dieckmann, Timo Steyer, Peer Trilcke, Niels Walkowski, Joëlle Weis, und Ulrike Wuttke. Wolfenbüttel. https://doi.org/10.17175/sb005_004
Chagué, Alix und Hugo Scheithauer. 2024. „ATR Schritt 4 – Layoutanalyse”. Automatic Text Recognition. Harmonising ATR Workflow, herausgegeben von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/category/layout-analysis
Chiffoleau, Floriane und Sarah Ondrasze. 2024a. „ATR Schritt 5 – Texterkennung und Post-ATR-Korrektur”. Automatic Text Recognition. Harmonising ATR Workflows, herausgegeben. von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/2145.
Chiffoleau, Floriane und Sarah Ondrasze. 2024b. „ATR Schritt 6 – Endformate und Wiederverwendung”. Automatic Text Recognition. Harmonising ATR Workflows, herausgegeben von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/439
Denicolò, Barbara, und Christina Antenhofer. 2024. „Von der Datenerfassung zur Annotation (Transkribus). Quellen erfassen, analysieren, transkribieren und annotieren“. In Digital Humanities in den Geschichtswissenschaften, herausgegeben von Christina Antenhofer, Christoph Kühberger, und Arno Strohmeyer, 125–142. utb 6116. Wien: Böhlau Verlag.
Souvay, Hippolyte und Larissa Wil. 2024. „ATR Schritt 3 – Pre-Processing und Bildoptimierung”. Automatic Text Recognition. Harmonising ATR Workflows, herausgegeben von Anne Baillot und Mareike König. Zuletzt aufgerufen am 05. Februar 2026. https://harmoniseatr.hypotheses.org/3742